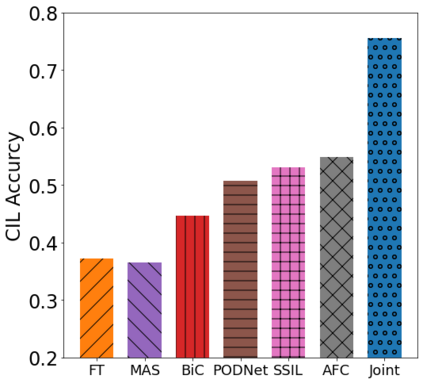
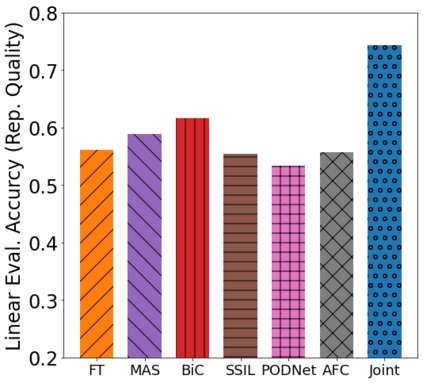
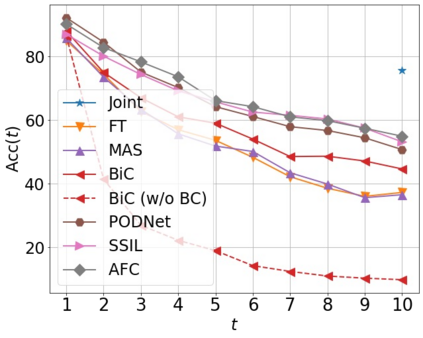
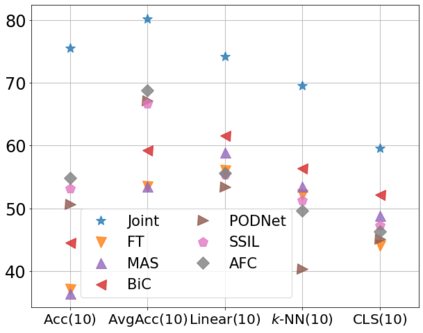
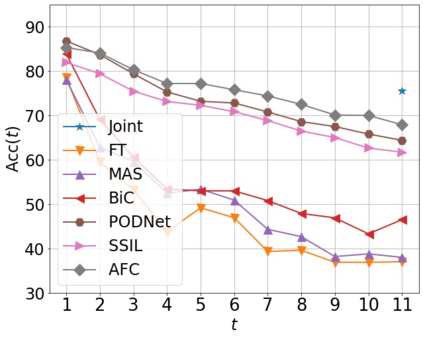
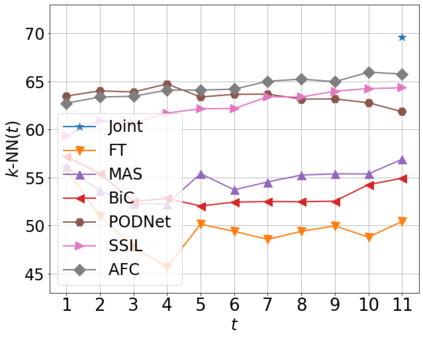
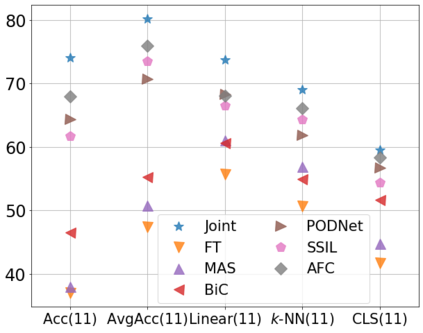
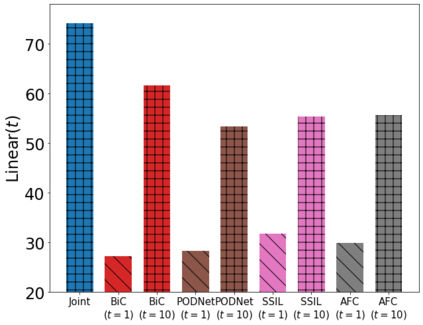
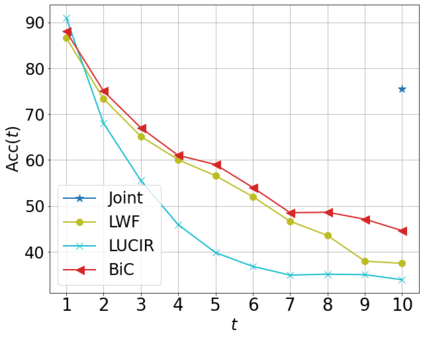
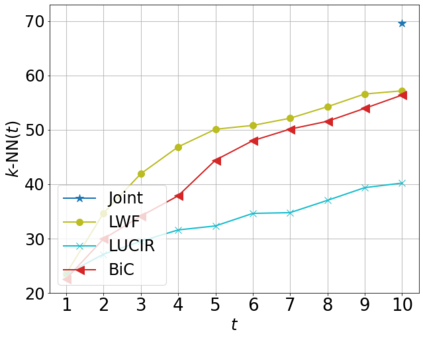
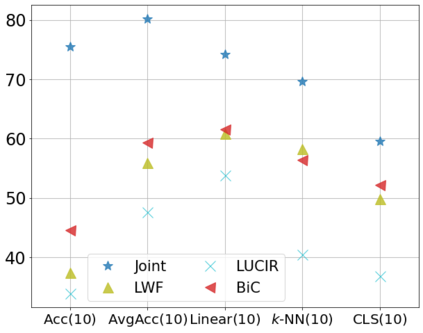
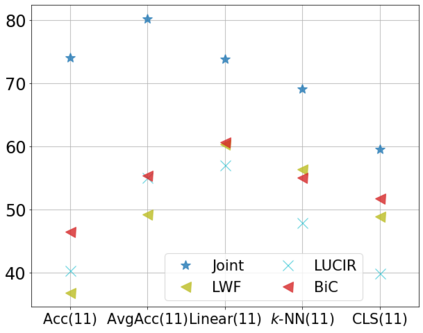
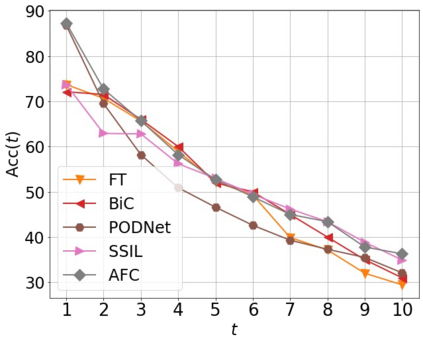
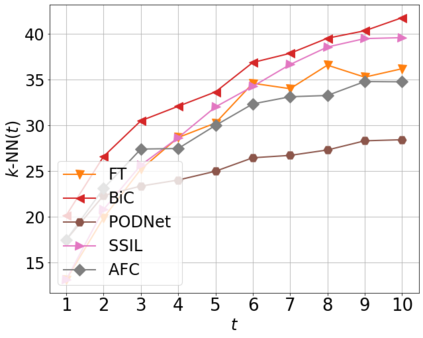
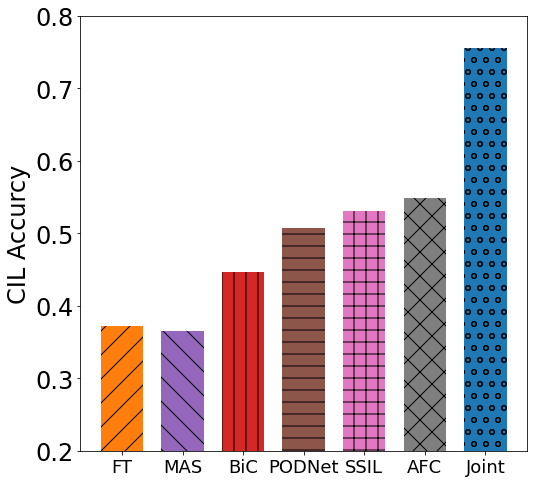
Class incremental learning (CIL) algorithms aim to continually learn new object classes from incrementally arriving data while not forgetting past learned classes. The common evaluation protocol for CIL algorithms is to measure the average test accuracy across all classes learned so far -- however, we argue that solely focusing on maximizing the test accuracy may not necessarily lead to developing a CIL algorithm that also continually learns and updates the representations, which may be transferred to the downstream tasks. To that end, we experimentally analyze neural network models trained by CIL algorithms using various evaluation protocols in representation learning and propose new analysis methods. Our experiments show that most state-of-the-art algorithms prioritize high stability and do not significantly change the learned representation, and sometimes even learn a representation of lower quality than a naive baseline. However, we observe that these algorithms can still achieve high test accuracy because they enable a model to learn a classifier that closely resembles an estimated linear classifier trained for linear probing. Furthermore, the base model learned in the first task, which involves single-task learning, exhibits varying levels of representation quality across different algorithms, and this variance impacts the final performance of CIL algorithms. Therefore, we suggest that the representation-level evaluation should be considered as an additional recipe for more diverse evaluation for CIL algorithms.
翻译:暂无翻译