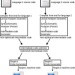
State-of-the-art sequential reasoning in Large Language Models (LLMs) has expanded the capabilities of Copilots beyond conversational tasks to complex function calling, managing thousands of API calls. However, the tendency of compositional prompting to segment tasks into multiple steps, each requiring a round-trip to the GPT APIs, leads to increased system latency and costs. Although recent advancements in parallel function calling have improved tool execution per API call, they may necessitate more detailed in-context instructions and task breakdown at the prompt level, resulting in higher engineering and production costs. Inspired by the hardware design principles of multiply-add (MAD) operations, which fuse multiple arithmetic operations into a single task from the compiler's perspective, we propose LLM-Tool Compiler, which selectively fuses similar types of tool operations under a single function at runtime, presenting them as a unified task to the LLM. This selective fusion inherently enhances parallelization and efficiency. Benchmarked on a large-scale Copilot platform, LLM-Tool Compiler achieves up to four times more parallel calls than existing methods, reducing token costs and latency by up to 40% and 12%, respectively.
翻译:暂无翻译