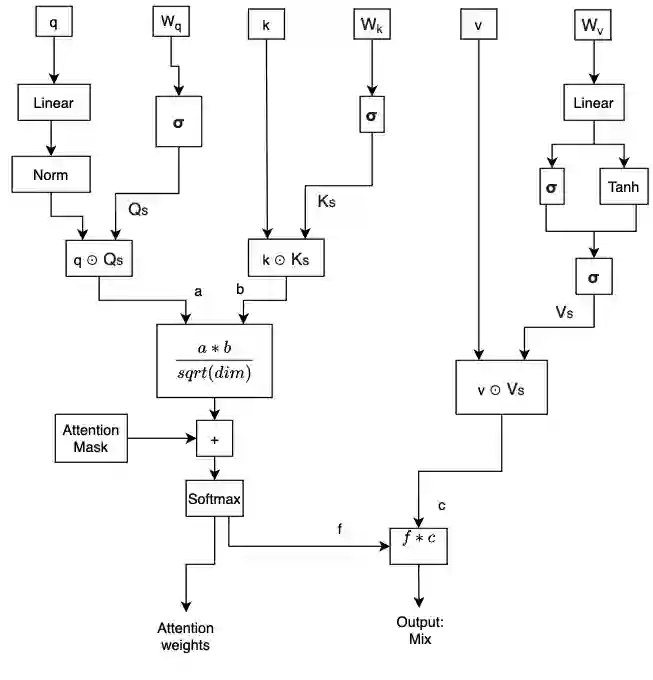
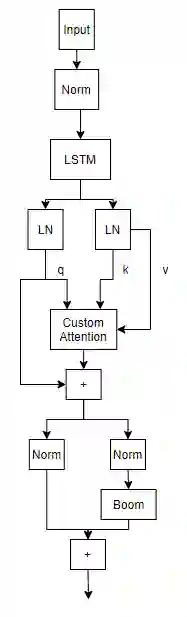
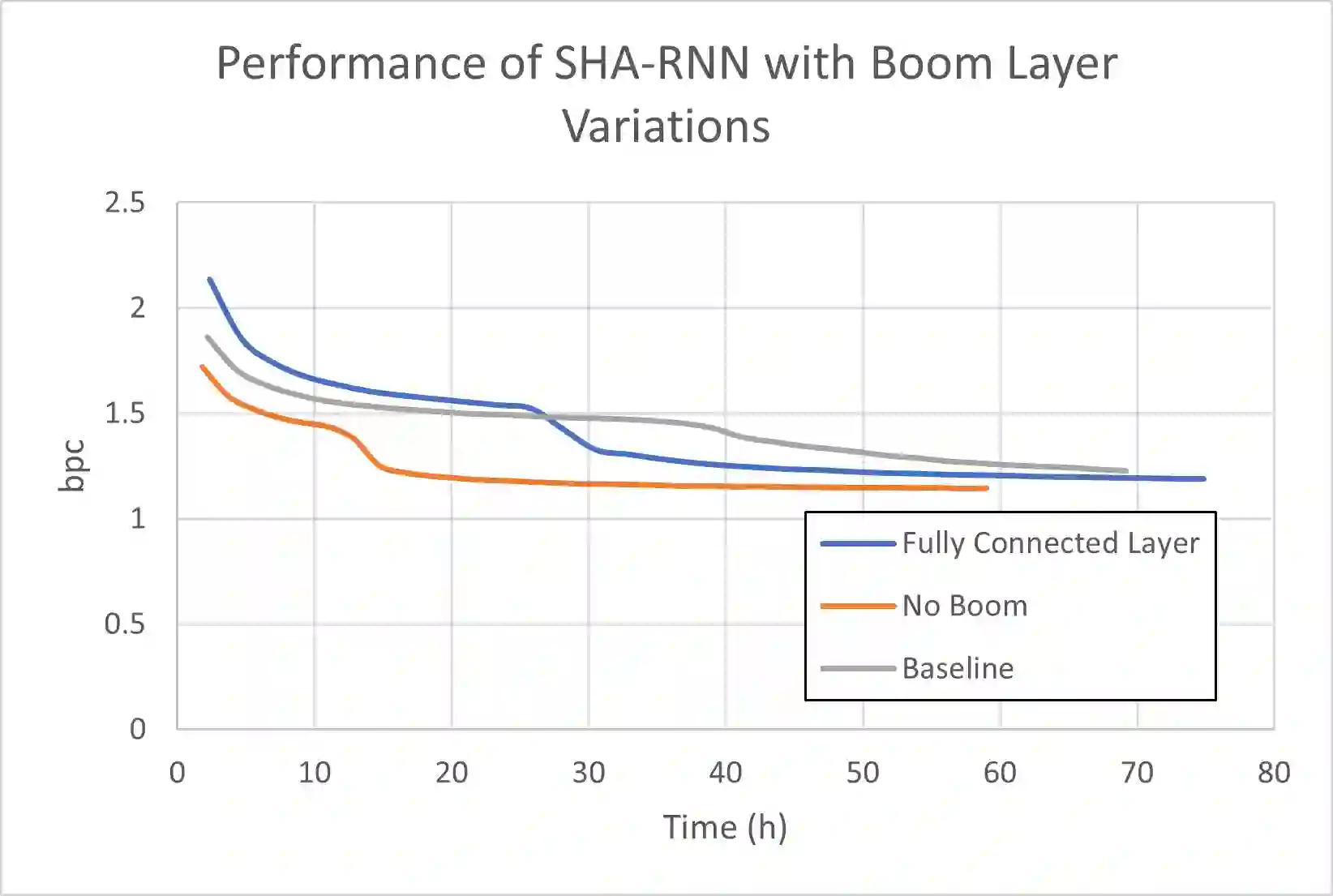
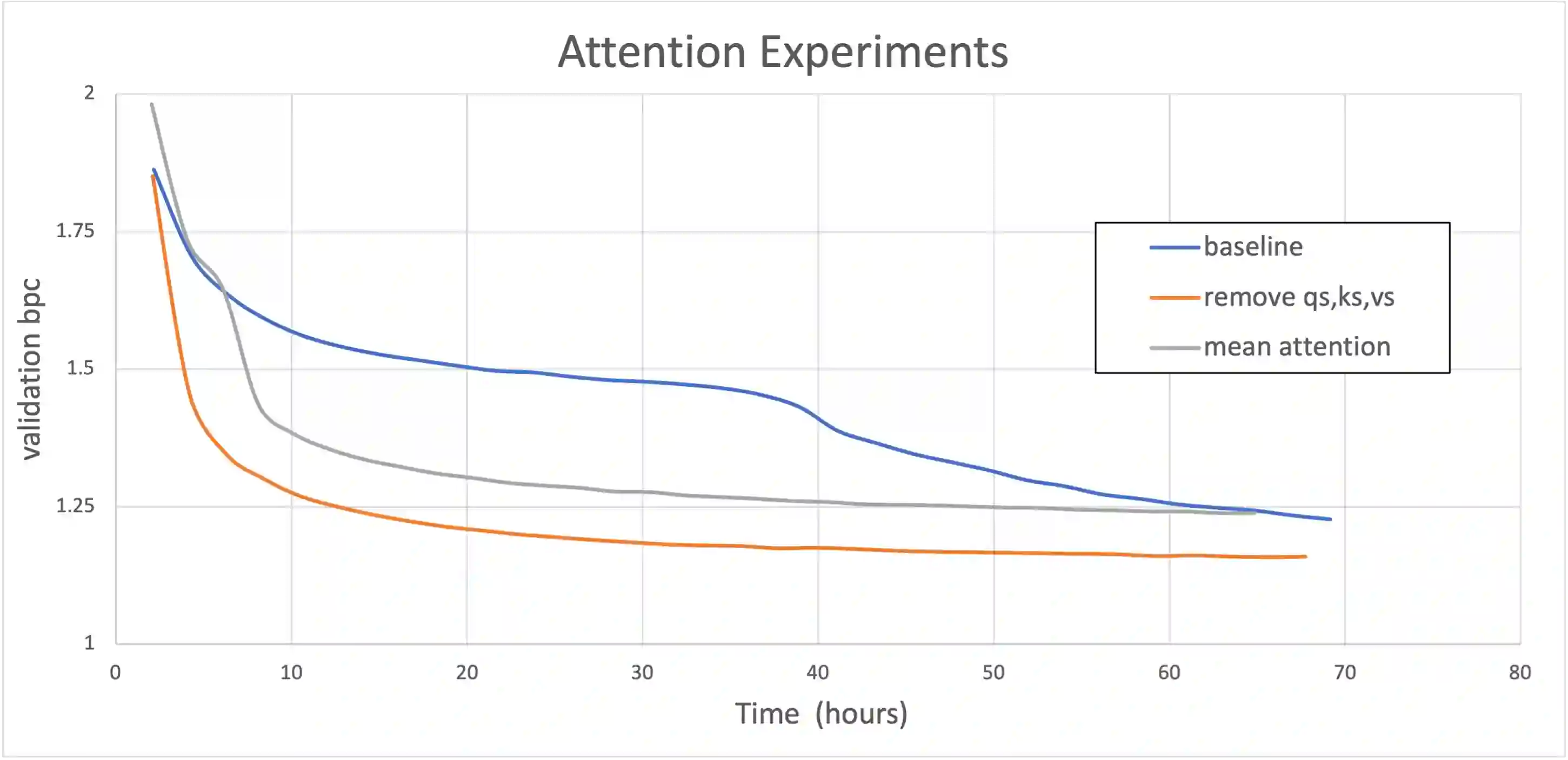
Natural Language Processing research has recently been dominated by large scale transformer models. Although they achieve state of the art on many important language tasks, transformers often require expensive compute resources, and days spanning to weeks to train. This is feasible for researchers at big tech companies and leading research universities, but not for scrappy start-up founders, students, and independent researchers. Stephen Merity's SHA-RNN, a compact, hybrid attention-RNN model, is designed for consumer-grade modeling as it requires significantly fewer parameters and less training time to reach near state of the art results. We analyze Merity's model here through an exploratory model analysis over several units of the architecture considering both training time and overall quality in our assessment. Ultimately, we combine these findings into a new architecture which we call SHAQ: Single Headed Attention Quasi-recurrent Neural Network. With our new architecture we achieved similar accuracy results as the SHA-RNN while accomplishing a 4x speed boost in training.
翻译:自然语言处理研究最近以大型变压器模式为主。 虽然变压器在很多重要语言任务上达到了最新水平, 但变压器往往需要昂贵的计算资源, 并且需要数周时间来培训。 对于大型科技公司和主要研究大学的研究人员来说, 这不可行, 但对于破旧的创业创始人、学生和独立研究人员来说则不可行。 Stephen Merity的SHA-RNN, 是一个紧凑的、混合关注-RNNN模型, 是为消费者级模型设计的, 因为它需要的参数要少得多, 培训时间也少一些, 才能达到接近最新水平。 我们在这里通过对考虑到培训时间和总体质量的数个建筑单位进行探索模型分析来分析优势模型。 最后, 我们把这些发现的结果合并成一个新的架构, 我们称之为 SHAQ: 单引力关注 准神经网络。 我们的新架构取得了类似于 SHA-RNNN, 同时在培训中实现了4x速度加速。