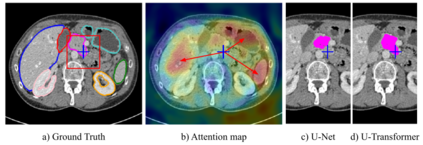
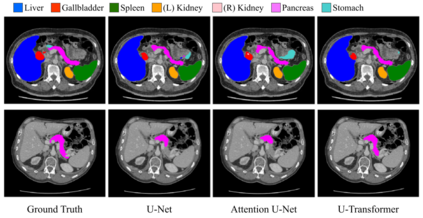
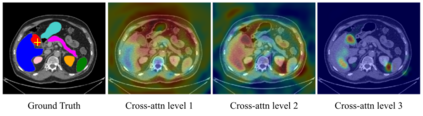
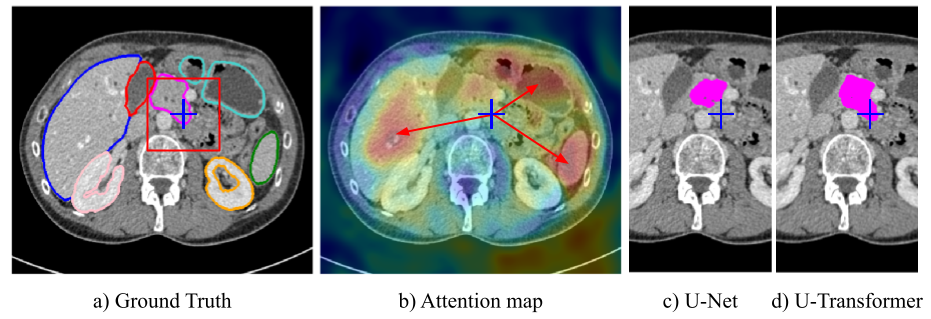
Medical image segmentation remains particularly challenging for complex and low-contrast anatomical structures. In this paper, we introduce the U-Transformer network, which combines a U-shaped architecture for image segmentation with self- and cross-attention from Transformers. U-Transformer overcomes the inability of U-Nets to model long-range contextual interactions and spatial dependencies, which are arguably crucial for accurate segmentation in challenging contexts. To this end, attention mechanisms are incorporated at two main levels: a self-attention module leverages global interactions between encoder features, while cross-attention in the skip connections allows a fine spatial recovery in the U-Net decoder by filtering out non-semantic features. Experiments on two abdominal CT-image datasets show the large performance gain brought out by U-Transformer compared to U-Net and local Attention U-Nets. We also highlight the importance of using both self- and cross-attention, and the nice interpretability features brought out by U-Transformer.
翻译:医疗图象分离对于复杂和低调解剖结构仍然特别具有挑战性。 在本文中,我们引入了U-Transent网络,将U型图象分离结构与来自变异器的自我和交叉注意结合起来。U-Transent克服了U-Net无法模拟长距离背景互动和空间依赖,这在具有挑战性的背景下对准确分割具有关键意义。为此,注意力机制在两个主要层面得到整合:自控模块利用编码功能之间的全球互动,而跳过连接的交叉注意通过过滤非二次线性特征,使得U-Net解密空间恢复良好。关于两个腹部CT图像数据集的实验显示U-Transor与U-Net和本地注意力U-Net之间的巨大性能收益。我们还强调了使用自控和交叉注意的重要性,以及U-Transtier带来的可读性特征。