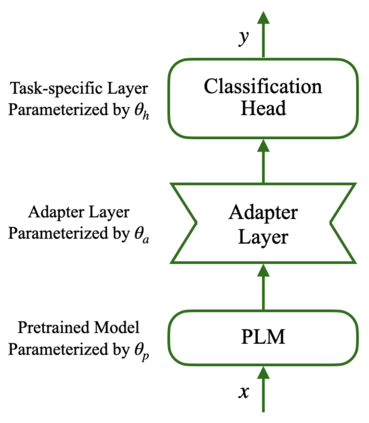
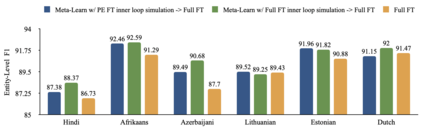
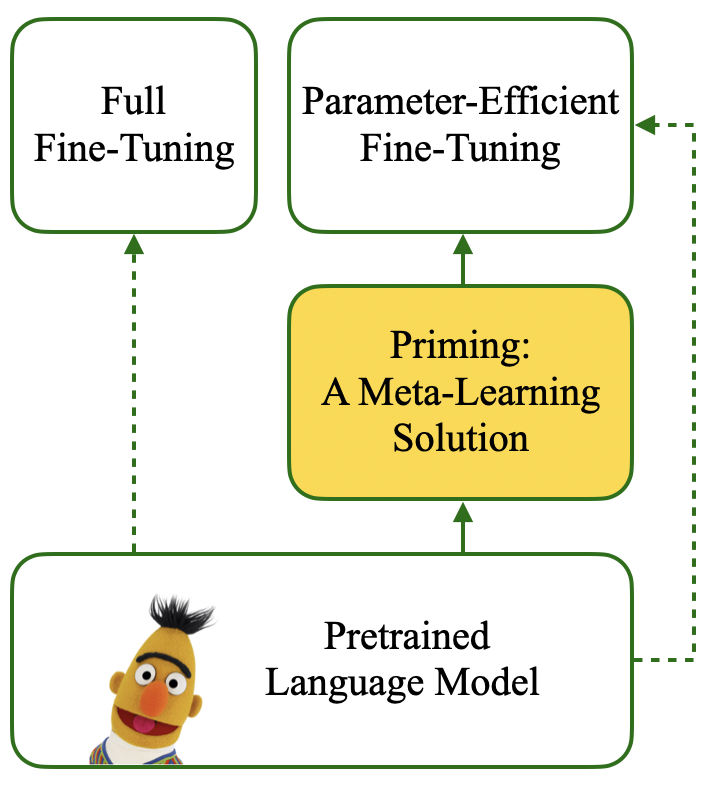
A recent family of techniques, dubbed lightweight fine-tuning methods, facilitates parameter-efficient transfer learning by updating only a small set of additional parameters while keeping the parameters of the pretrained language model frozen. While proven to be an effective method, there are no existing studies on if and how such knowledge of the downstream fine-tuning approach should affect the pretraining stage. In this work, we show that taking the ultimate choice of fine-tuning method into consideration boosts the performance of parameter-efficient fine-tuning. By relying on optimization-based meta-learning using MAML with certain modifications for our distinct purpose, we prime the pretrained model specifically for parameter-efficient fine-tuning, resulting in gains of up to 1.7 points on cross-lingual NER fine-tuning. Our ablation settings and analyses further reveal that the tweaks we introduce in MAML are crucial for the attained gains.
翻译:最近的一系列技术,即所谓的轻量级微调方法,通过只更新一小套附加参数,同时保持预先培训的语言模式的参数冻结,便利了参数效率转让学习。虽然事实证明这是一种有效方法,但目前还没有研究下游微调方法的这种知识是否以及如何影响培训前阶段。在这项工作中,我们表明,将微调方法的最终选择纳入考虑将提高参数效率微调的性能。通过利用基于优化的元化学习,并对我们的独特目的作某些修改,我们特别为参数效率微调提供预先培训的模型,从而在跨语言净化微调方面获得高达1.7个百分点的收益。我们的减速设置和分析进一步表明,我们在MAML中引入的tweak对于实现的收益至关重要。