![]()
©PaperWeekly 原创 · 作者 | 避暑山庄梁朝伟
研究方向 | 自然语言处理
![]()
背景
随着计算算力的不断增加,以 transformer 为主要架构的预训练模型进入了百花齐放的时代。看到了大规模预训练的潜力,尝试了不同的预训练任务、模型架构、训练策略等等,在做这些探索之外,一个更加直接也通常更加有效的方向就是继续增大数据量和模型容量来向上探测这一模式的上界。首先这些经过海量数据训练的模型相比于一般的深度模型而言,包含更多的参数,动辄数十亿。在针对不同下游任务做微调时,存储(每个任务对应一个完成的预训练模型)和训练这种大模型是十分昂贵且耗时的。
![]()
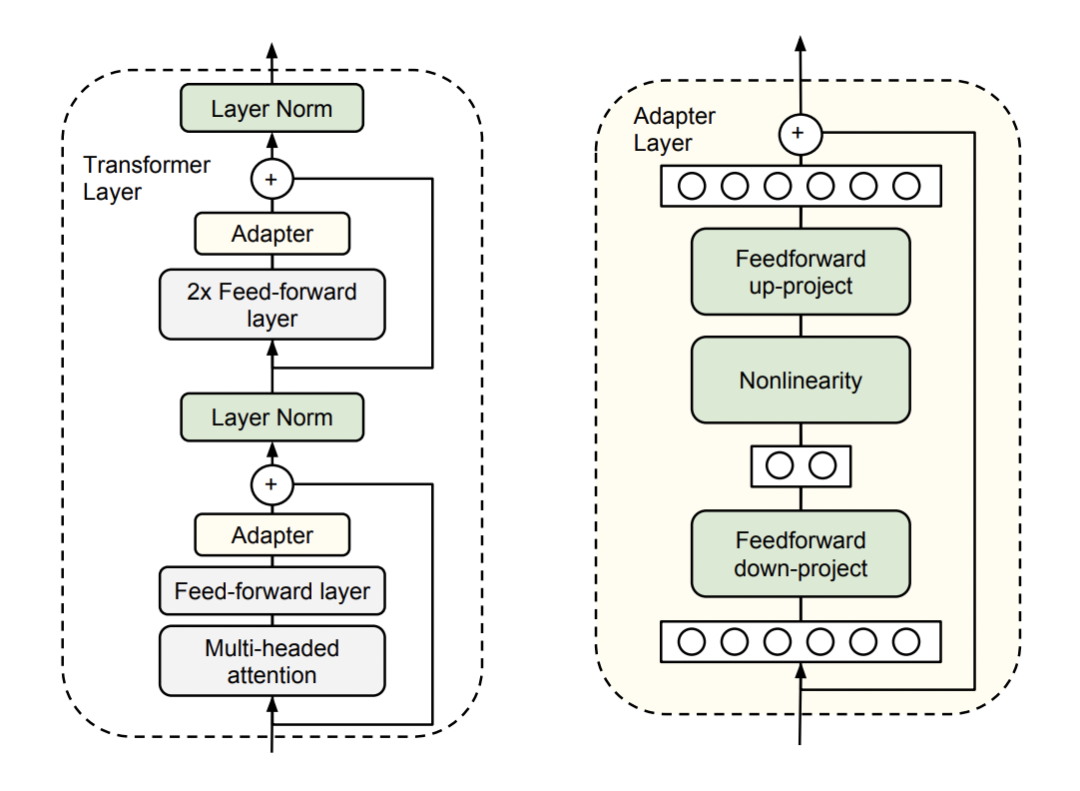
通过过在原始的预训练模型中的每个 transformer block 中加入一些参数可训练的模块实现的。假设原始的预训练模型的参数为 ω,加入的 adapter 参数为 υ,在针对不同下游任务进行调整时,只需要将预训练参数固定住,只针对 adapter 参数 υ 进行训练。常情况下,参数量 υ<<ω, 因此在对多个下游任务调整时,只需要调整极小数量的参数,大大的提高了预训练模型的扩展性和实用性。
![]()
论文标题:
Parameter-Efficient Transfer Learning for NLP
论文链接:
https://arxiv.org/abs/1902.00751
代码链接:
https://github.com/google-research/adapter-bert
在 Multi-head attention 层后和 FFN 层后都加了一个 adapter,通过残差连接和 down-project & up-project(减少 adapter 的参数量)实现。
![]()
![]()
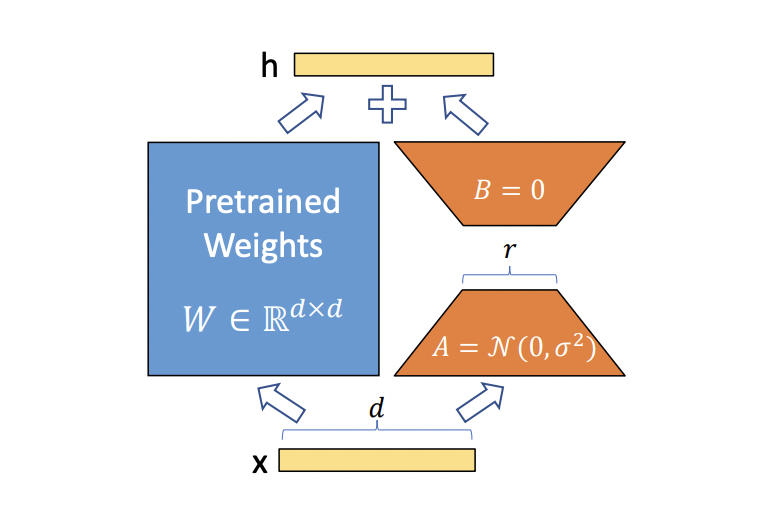
LoRA: Low-Rank Adaptation of Large Language Models
https://arxiv.org/abs/2106.09685
https://github.com/microsoft/LoRA
将原有预训练参数进行矩阵分解(减少参数量),然后和原有参数相加。
![]()
2.2 Part Parameter Tuning
通过训练预训练模型中部分参数,减少模型训练参数,提升模型训练效率,其中包括 layernorm&head tune(只训练模型的 layernorm 和 head 层)等。
![]()
论文标题:
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
论文链接:
https://arxiv.org/abs/2106.10199
代码链接:
https://github.com/benzakenelad/BitFit
模型 head 层增加一层线性映射,通过先验非有效输入样本预估平衡(各 50% 概率进行校准)。
![]()
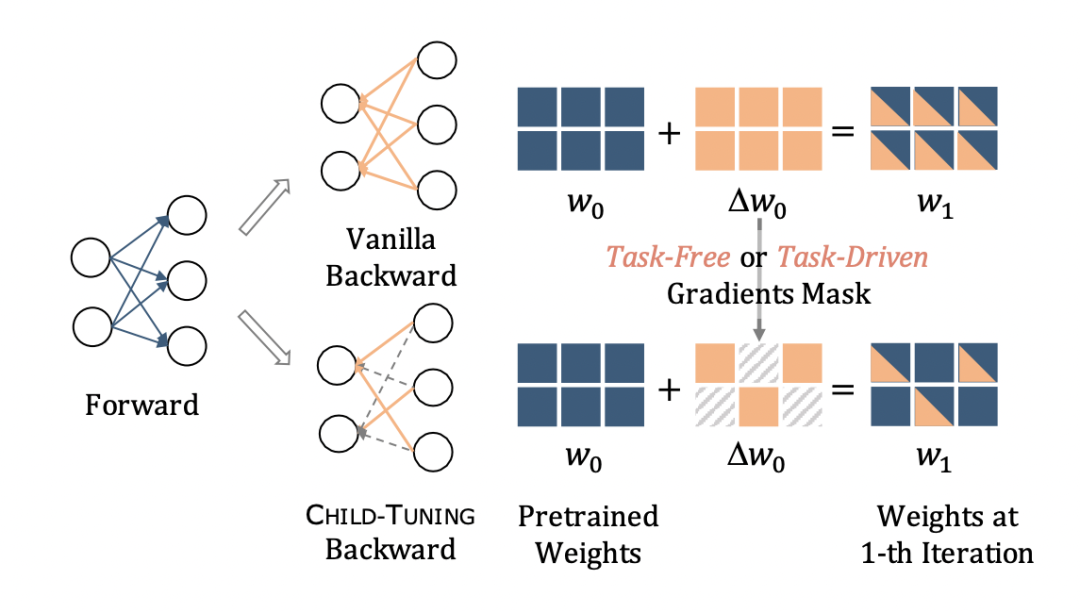
Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning
https://arxiv.org/abs/2109.05687
https://github.com/pkunlp-icler/childtuning
Child-Tuning-F:在 fine-tune 的过程中,只需要在每一步更新的迭代中,从伯努利分布中采样得到一个梯度掩模即可,相当于在对网络参数更新的时候随机地将一部分梯度丢弃。
Child-Tuning-D:针对不同的下游任务自适应地进行调整,选择出与下游任务最相关最重要的参数来充当 Child Network。引入 Fisher Information Matrix(FIM)来估计每个参数对于下游任务的重要性程度,并与前人工作一致近似采用 FIM 的对角矩阵(即假设参数之间互相独立)来计算各个参数相对下游任务的重要性分数,之后选择分数最高的那部分参数作为 Child-Network。
![]()
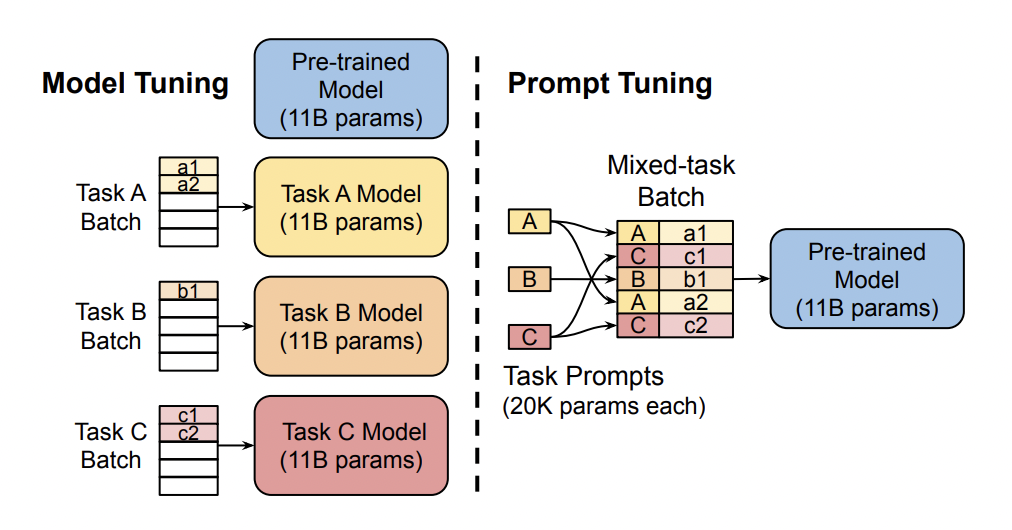
固定预训练模型,每个下游任务仅添加若干个 tunable 的 token 作为前缀拼在输入样本中。实验证明了这种方式在大规模预训练模型的助力下,能够媲美传统的 fine-tuning 表现。
![]()
Prefix-Tuning: Optimizing Continuous Prompts for Generation
https://arxiv.org/abs/2101.00190
https://github.com/XiangLi1999/PrefixTuning
将 soft tokens 作为前缀拼在输入样本中,并且拼在每一层中。
![]()
The Power of Scale for Parameter-Efficient Prompt Tuning
https://arxiv.org/abs/2104.08691
https://github.com/google-research/prompt-tuning
在百亿参数和以上模型在 full-shot 上使得 Prompt Tuning 和 fine-tuning 效果相当。
![]()
![]()
PPT: Pre-trained Prompt Tuning for Few-shot Learning
https://arxiv.org/abs/2109.04332
提出 prompt 预训练,在百亿参数和以上模型在 few-shot 上使得 Prompt Tuning 和 fine-tuning 效果相当。
![]()
![]()
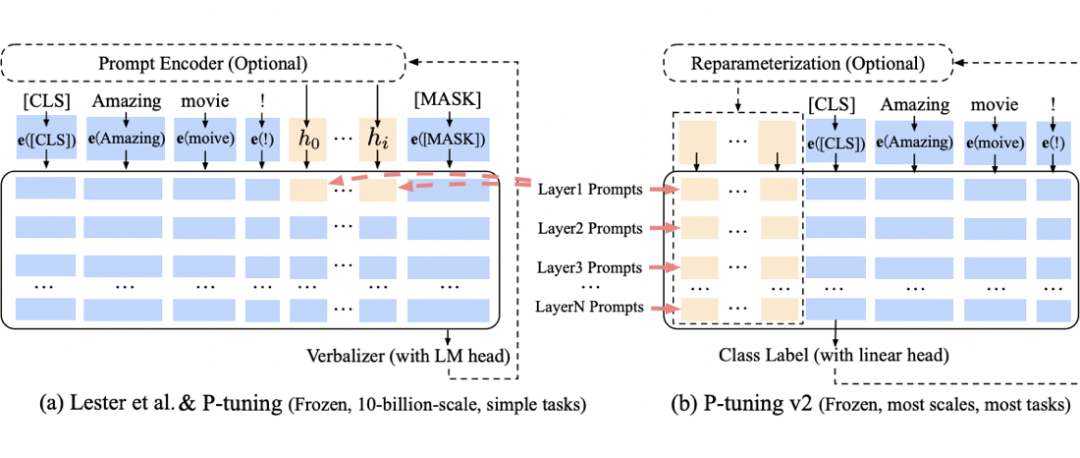
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
https://arxiv.org/abs/2110.07602
https://github.com/THUDM/P-tuning-v2
在低于百亿参数模型在 full-shot 上使得 Prompt Tuning 和 fine-tuning 效果相当,引入了 prefix-tuning。
![]()
![]()
Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models
https://arxiv.org/abs/2106.13353
https://github.com/ucinlp/null-prompts
在低于百亿参数模型在 few-shot 上使得 Prompt Tuning 和 fine-tuning 效果相当,并且提出 null prompt 方法
![]()
![]()
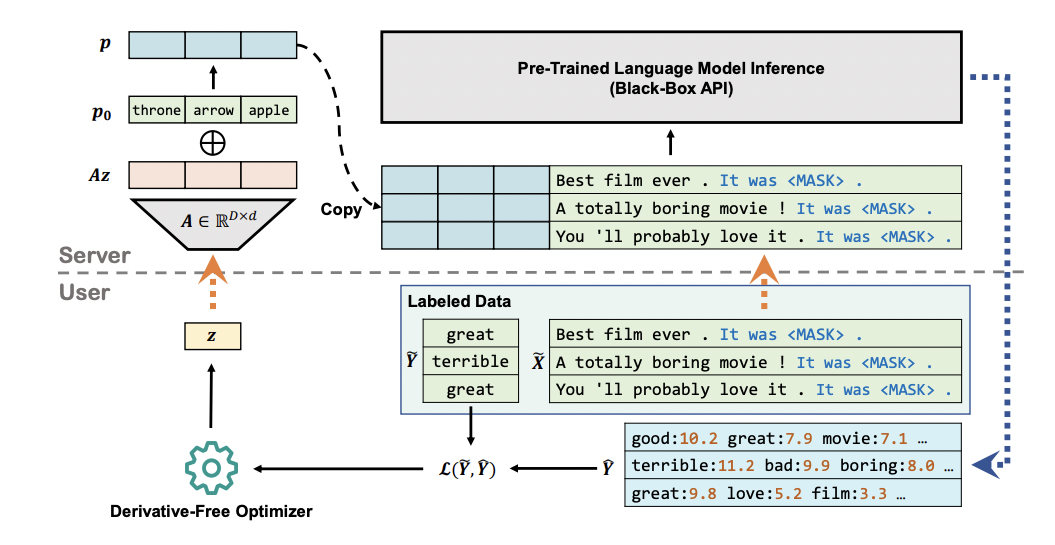
Black-Box Tuning for Language-Model-as-a-Service
https://arxiv.org/abs/2201.03514
https://github.com/txsun1997/black-box-tuning
通过将 prompt token 压缩到比较小的维度,然后通过无梯度优化方法进行参数调优,避免了在大模型梯度下降,只需要用户根据少量样本走预训练模型前向的结果来寻找最优的任务参数。这种方式非常有利于大模型落地,用户和大模型之间进行分离。
![]()
![]()
Towards a Unified View of Parameter-Efficient Transfer Learning
https://arxiv.org/abs/2110.04366
https://github.com/jxhe/unified-parameter-efficient-tuning
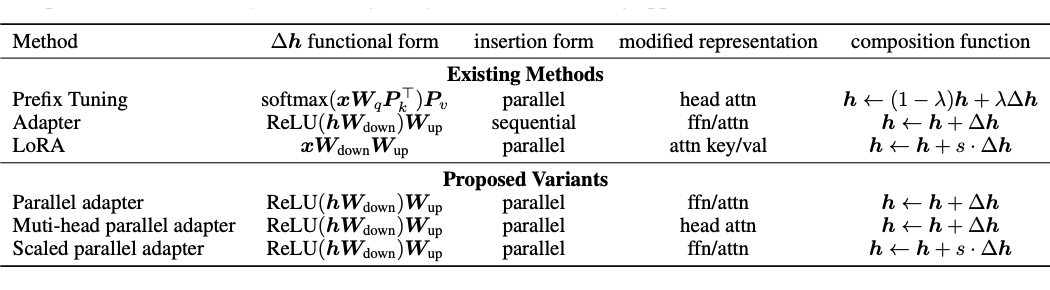
prefix tuning 通过一些变换可以看成是和 Adapter 类似的结构,可以把它们看作是学习一个向量
,它被应用于各种隐藏表征。形式上,直接修改的隐藏表征表示为
,把计算
的 PLM 子模块的直接输入表示为
。
![]()
-
Parallel Adapter 在所有情况下都能够击败 Sequential Adapter;
适配修改放在 Transformer 的 attention 模块效果更佳。
![]()
随着预训练大模型的发展,高效 Parameter Finetuning 是非常必要的,近期大火的 prompt 也发展着越来越像之前的 adapter 方法。希望随着方法越来越成熟,能研究在各项任务设置和模型规模上打平 finetune 的方法。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()