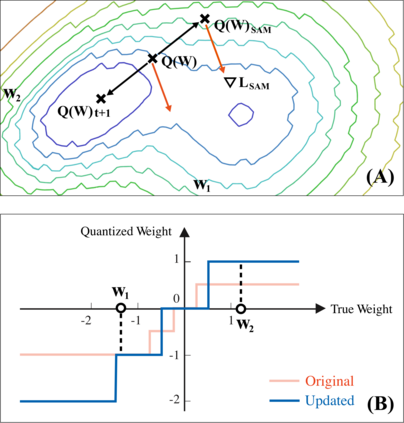
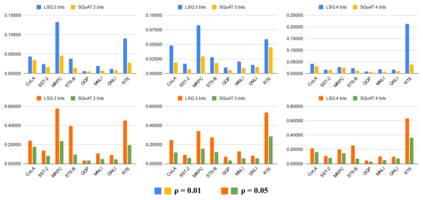
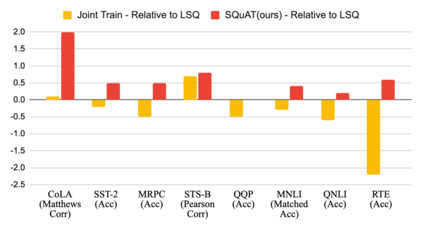
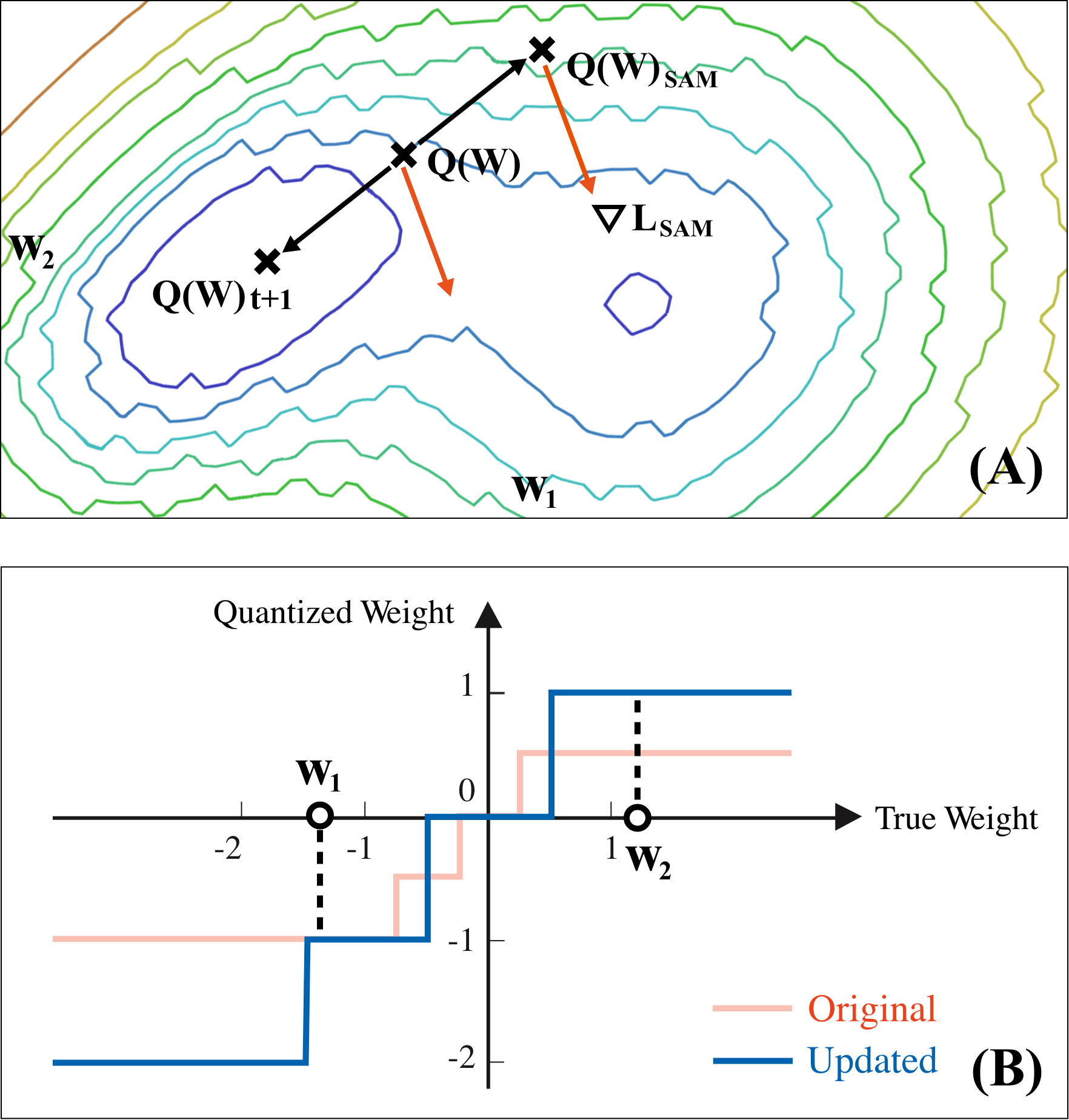
Quantization is an effective technique to reduce memory footprint, inference latency, and power consumption of deep learning models. However, existing quantization methods suffer from accuracy degradation compared to full-precision (FP) models due to the errors introduced by coarse gradient estimation through non-differentiable quantization layers. The existence of sharp local minima in the loss landscapes of overparameterized models (e.g., Transformers) tends to aggravate such performance penalty in low-bit (2, 4 bits) settings. In this work, we propose sharpness- and quantization-aware training (SQuAT), which would encourage the model to converge to flatter minima while performing quantization-aware training. Our proposed method alternates training between sharpness objective and step-size objective, which could potentially let the model learn the most suitable parameter update magnitude to reach convergence near-flat minima. Extensive experiments show that our method can consistently outperform state-of-the-art quantized BERT models under 2, 3, and 4-bit settings on GLUE benchmarks by 1%, and can sometimes even outperform full precision (32-bit) models. Our experiments on empirical measurement of sharpness also suggest that our method would lead to flatter minima compared to other quantization methods.
翻译:量化是减少记忆足迹、推推延率和深层学习模型动力消耗的有效方法。然而,现有量化方法与全精度模型相比,精确度下降,因为粗粗梯度估算通过非差别量化层引入错误。超分模型(如变压器)损失地貌中存在尖锐的地方微粒,往往会加重低位(2、4比特)环境中的这种性能处罚。在这项工作中,我们建议精确度和定量认知模型培训(SQAAT),这将鼓励该模型在进行四分法培训时与微米相融合。我们提议的方法替代了精确度目标与跨级目标之间的培训。这有可能让模型学习最合适的参数更新程度,以达到接近缩放微型模型的趋同量。广泛的实验表明,我们的方法在2、3和4位模型下,GLUE基准下的精度和微量度(SQUE基准)会鼓励该模型在进行微量度培训时与微量度模型相趋近,有时甚至可以建议我们最精确的精确度测量方法。