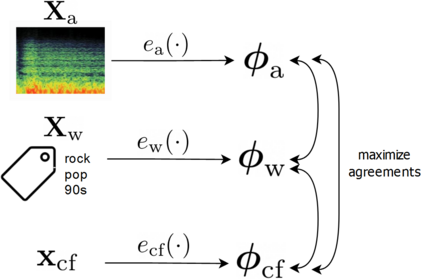
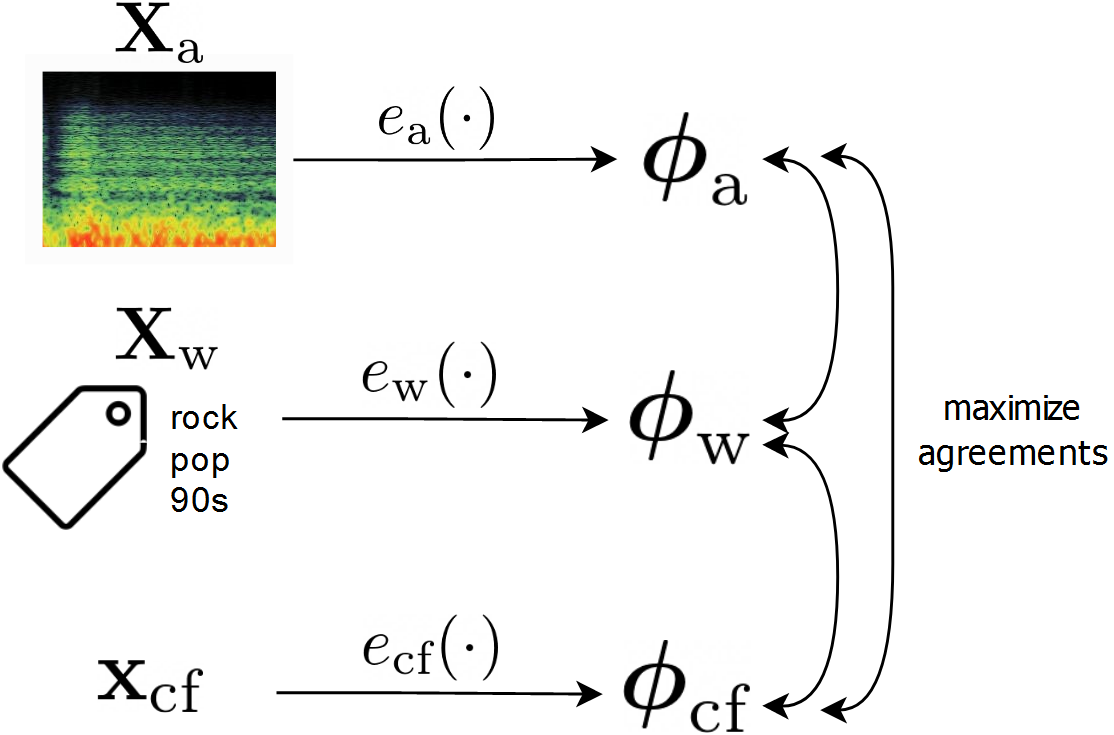
Modeling various aspects that make a music piece unique is a challenging task, requiring the combination of multiple sources of information. Deep learning is commonly used to obtain representations using various sources of information, such as the audio, interactions between users and songs, or associated genre metadata. Recently, contrastive learning has led to representations that generalize better compared to traditional supervised methods. In this paper, we present a novel approach that combines multiple types of information related to music using cross-modal contrastive learning, allowing us to learn an audio feature from heterogeneous data simultaneously. We align the latent representations obtained from playlists-track interactions, genre metadata, and the tracks' audio, by maximizing the agreement between these modality representations using a contrastive loss. We evaluate our approach in three tasks, namely, genre classification, playlist continuation and automatic tagging. We compare the performances with a baseline audio-based CNN trained to predict these modalities. We also study the importance of including multiple sources of information when training our embedding model. The results suggest that the proposed method outperforms the baseline in all the three downstream tasks and achieves comparable performance to the state-of-the-art.
翻译:使音乐片具有独特性的各个方面建模是一项具有挑战性的任务,需要多种信息来源的组合。深层次学习通常用于利用各种信息来源,例如音频、用户和歌曲之间的互动或相关的元元数据等,获得各种表述。最近,对比式学习导致与传统监督方法相比,更普遍化的表述。在本文中,我们提出了一个新颖的方法,将多种类型的音乐信息结合起来,利用交叉模式的对比学习,使我们能够同时从多种数据中学习一个音频特征。我们通过利用对比性损失,最大限度地实现这些模式的表述之间的一致,将来自播放式互动、基因元数据和音频的潜在表述相匹配。我们评估了我们三种任务的方法,即基因分类、播放列表延续和自动标记。我们比较了业绩与基线的有线电视新闻网所训练的预测这些模式。我们还研究了在培训我们嵌入模型时纳入多种信息来源的重要性。结果显示,拟议方法超越了所有三个下游任务的基线,并实现了与状态相似的业绩。