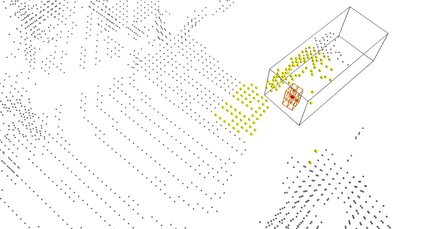
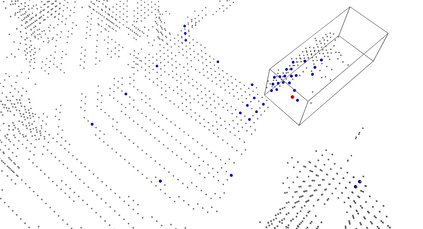
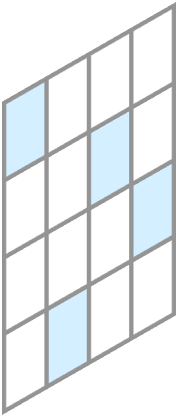
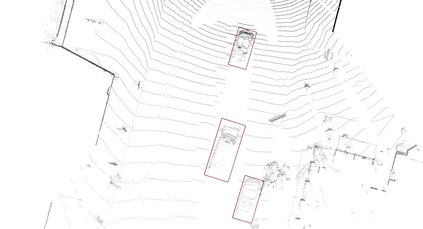
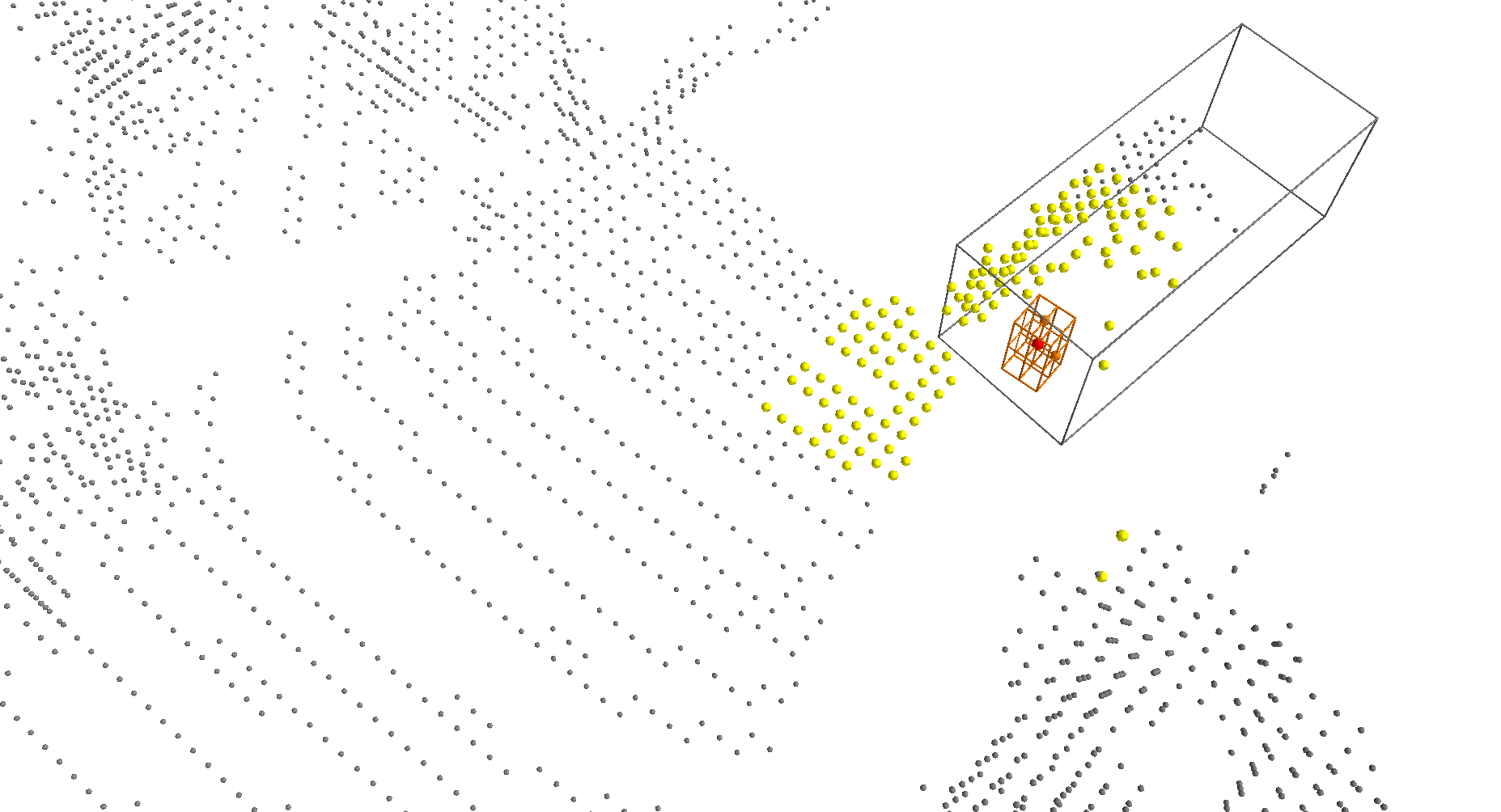
We present Voxel Transformer (VoTr), a novel and effective voxel-based Transformer backbone for 3D object detection from point clouds. Conventional 3D convolutional backbones in voxel-based 3D detectors cannot efficiently capture large context information, which is crucial for object recognition and localization, owing to the limited receptive fields. In this paper, we resolve the problem by introducing a Transformer-based architecture that enables long-range relationships between voxels by self-attention. Given the fact that non-empty voxels are naturally sparse but numerous, directly applying standard Transformer on voxels is non-trivial. To this end, we propose the sparse voxel module and the submanifold voxel module, which can operate on the empty and non-empty voxel positions effectively. To further enlarge the attention range while maintaining comparable computational overhead to the convolutional counterparts, we propose two attention mechanisms for multi-head attention in those two modules: Local Attention and Dilated Attention, and we further propose Fast Voxel Query to accelerate the querying process in multi-head attention. VoTr contains a series of sparse and submanifold voxel modules and can be applied in most voxel-based detectors. Our proposed VoTr shows consistent improvement over the convolutional baselines while maintaining computational efficiency on the KITTI dataset and the Waymo Open dataset.
翻译:我们展示了Voxel 变形器(Voxel 变形器)(VoTr ), 这是一种新颖而有效的Voxel 变形器(VoTr ), 用于从点云中检测 3D 3D 探测器中的常规 3D 3D 变形主干网无法有效捕捉大背景信息, 这对于天体识别和本地化至关重要, 因为可接受字段有限。 在本文件中, 我们通过引入一个基于变形器的架构来解决这个问题, 使 voxel 之间能够通过自我关注实现长距离关系。 鉴于非空的 voxel 变形器自然稀疏, 但数量众多, 直接对 voxel 直接应用标准变形器是非三角的。 为此, 我们提议了稀疏的 voxel 变形变形器模块和 子折叠式 vurx 模块, 能够有效地在空的和无孔体变形变形体位置位置上运行。 为了进一步扩大关注范围,同时保持与变形变形变形变形变形的计算模型中的拟议数据序列 。 Vorttrax 将显示我们的变式变式变式的变式变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式的变式, 。