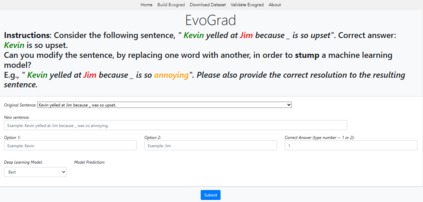
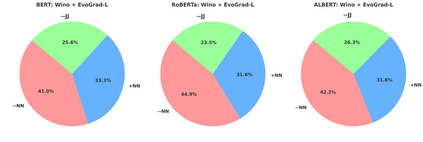
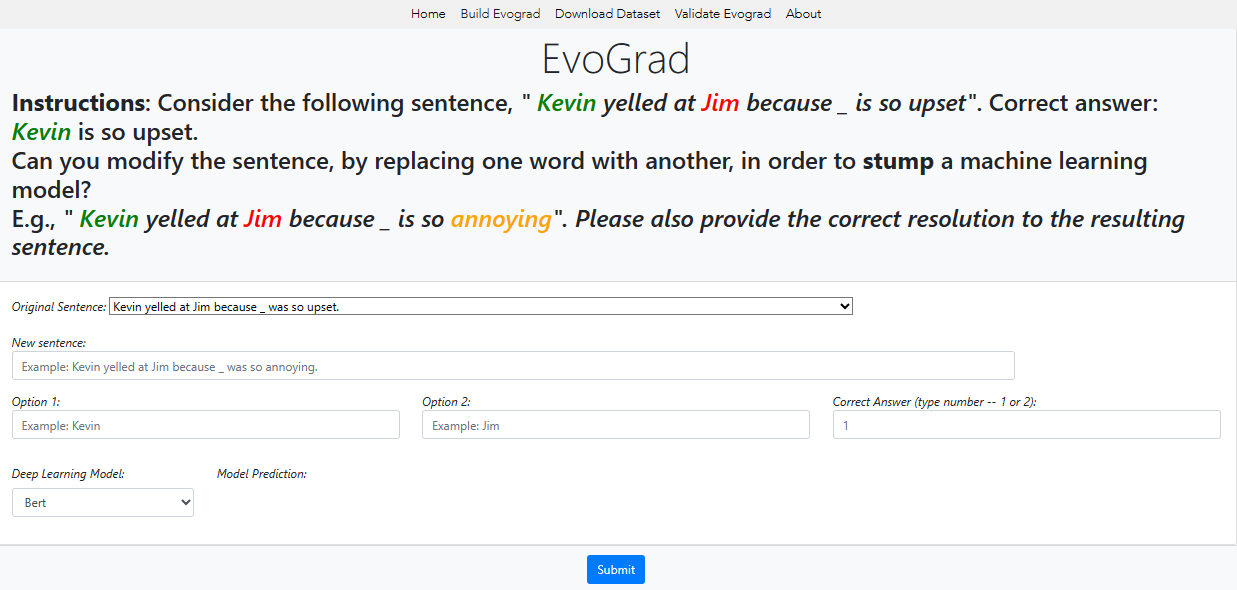
While Large Language Models (LLMs) excel at the Winograd Schema Challenge (WSC), a coreference resolution task testing common-sense reasoning through pronoun disambiguation, they struggle with instances that feature minor alterations or rewording. To address this, we introduce EvoGrad, an open-source platform that harnesses a human-in-the-loop approach to create a dynamic dataset tailored to such altered WSC instances. Leveraging ChatGPT's capabilities, we expand our task instances from 182 to 3,691, setting a new benchmark for diverse common-sense reasoning datasets. Additionally, we introduce the error depth metric, assessing model stability in dynamic tasks. Our results emphasize the challenge posed by EvoGrad: Even the best performing LLM, GPT-3.5, achieves an accuracy of 65.0% with an average error depth of 7.2, a stark contrast to human performance of 92. 8% accuracy without perturbation errors. This highlights ongoing model limitations and the value of dynamic datasets in uncovering them.
翻译:暂无翻译