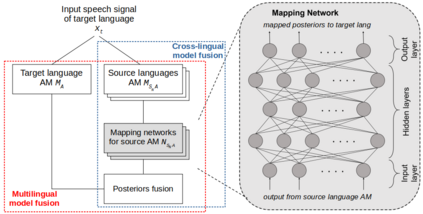
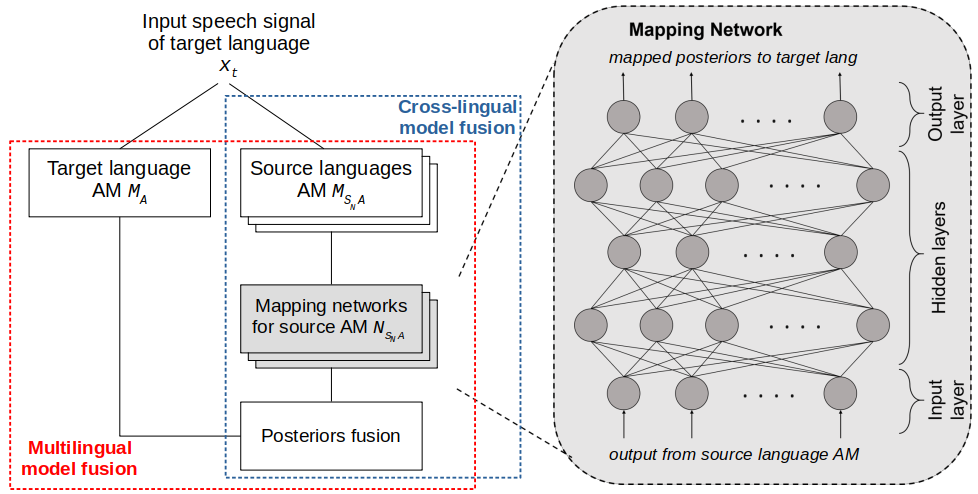
Multilingual speech recognition has drawn significant attention as an effective way to compensate data scarcity for low-resource languages. End-to-end (e2e) modelling is preferred over conventional hybrid systems, mainly because of no lexicon requirement. However, hybrid DNN-HMMs still outperform e2e models in limited data scenarios. Furthermore, the problem of manual lexicon creation has been alleviated by publicly available trained models of grapheme-to-phoneme (G2P) and text to IPA transliteration for a lot of languages. In this paper, a novel approach of hybrid DNN-HMM acoustic models fusion is proposed in a multilingual setup for the low-resource languages. Posterior distributions from different monolingual acoustic models, against a target language speech signal, are fused together. A separate regression neural network is trained for each source-target language pair to transform posteriors from source acoustic model to the target language. These networks require very limited data as compared to the ASR training. Posterior fusion yields a relative gain of 14.65% and 6.5% when compared with multilingual and monolingual baselines respectively. Cross-lingual model fusion shows that the comparable results can be achieved without using posteriors from the language dependent ASR.
翻译:多语言语言的承认作为弥补低资源语言数据稀缺的有效途径,引起了人们的极大关注。主要因为没有词汇要求,端到端(e2e)建模优于常规混合系统,主要因为没有词汇要求。不过,在有限的数据假设情况下,混合的DNN-HMM-MM-MM-MM-MM-MM-MSP仍然优于e2e2e-e2e模型;此外,手动词汇创建问题已经通过公开提供的经过培训的石墨到语音模型(G2P)和文本转换成IPPA许多语言的文本而得到缓解。在本文中,在为低资源语言建立的多语种设置中,建议采用混合的DNNN-HMM的声学模型(e2e)模型。不同单一语言的声学模型对目标语言语言语音语音信号的外源分布是结合的。对每种源目标语言配对进行单独的回归神经网络进行了培训,以将后方语言从源声模型转换成目标语言。这些网络需要与ASR培训相比,需要非常有限的数据。骨质聚合聚合聚合组合产生14.65%和6.5%的相对收益,而与单语言基准相比,可以比较从多语和单语言分别从多语言模型展示。