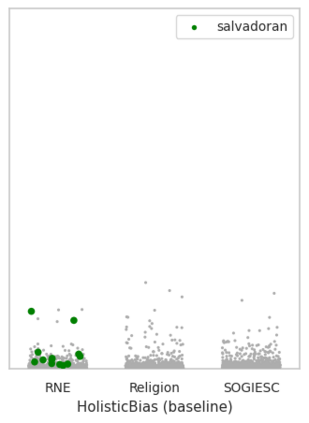
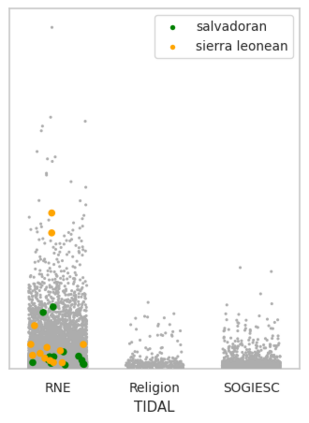
Machine learning models can perpetuate unintended biases from unfair and imbalanced datasets. Evaluating and debiasing these datasets and models is especially hard in text datasets where sensitive attributes such as race, gender, and sexual orientation may not be available. When these models are deployed into society, they can lead to unfair outcomes for historically underrepresented groups. In this paper, we present a dataset coupled with an approach to improve text fairness in classifiers and language models. We create a new, more comprehensive identity lexicon, TIDAL, which includes 15,123 identity terms and associated sense context across three demographic categories. We leverage TIDAL to develop an identity annotation and augmentation tool that can be used to improve the availability of identity context and the effectiveness of ML fairness techniques. We evaluate our approaches using human contributors, and additionally run experiments focused on dataset and model debiasing. Results show our assistive annotation technique improves the reliability and velocity of human-in-the-loop processes. Our dataset and methods uncover more disparities during evaluation, and also produce more fair models during remediation. These approaches provide a practical path forward for scaling classifier and generative model fairness in real-world settings.
翻译:暂无翻译