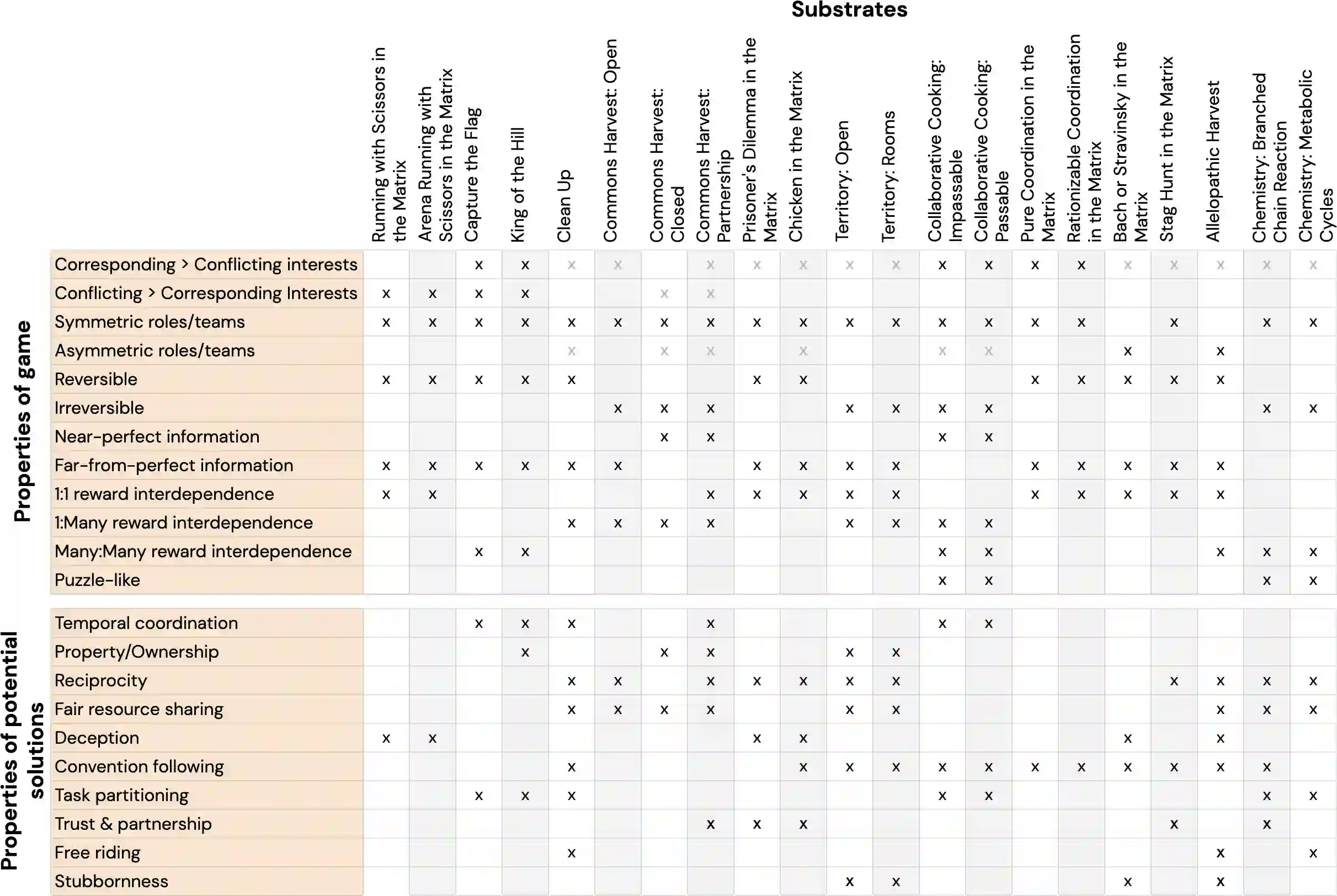
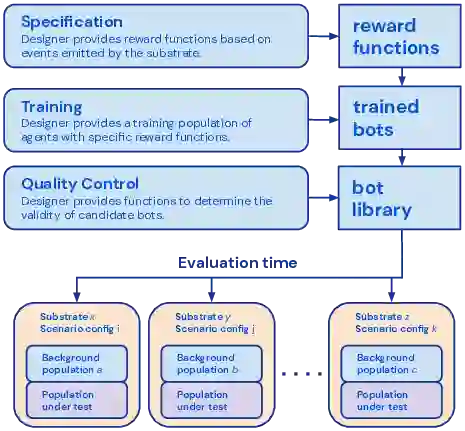
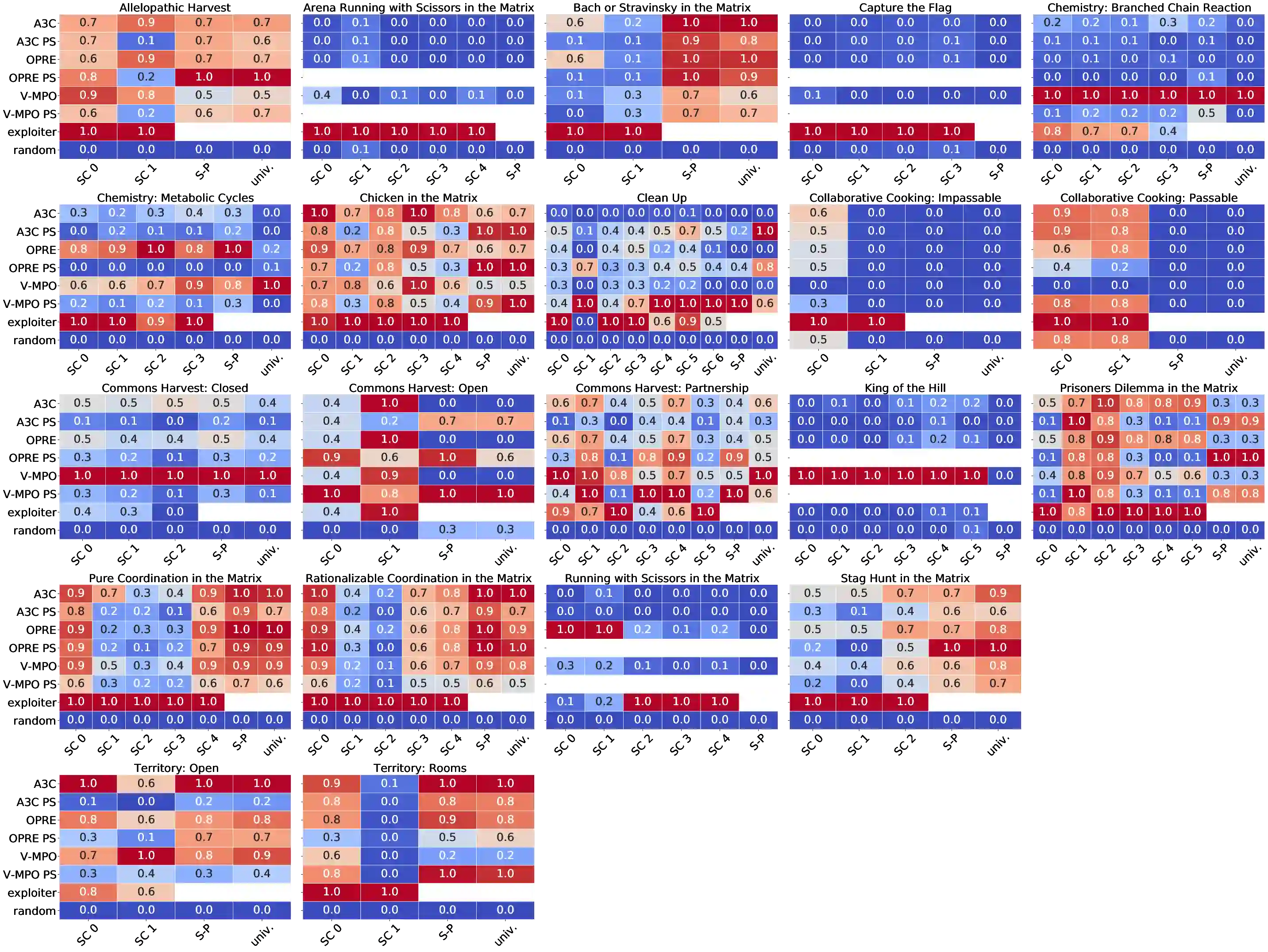
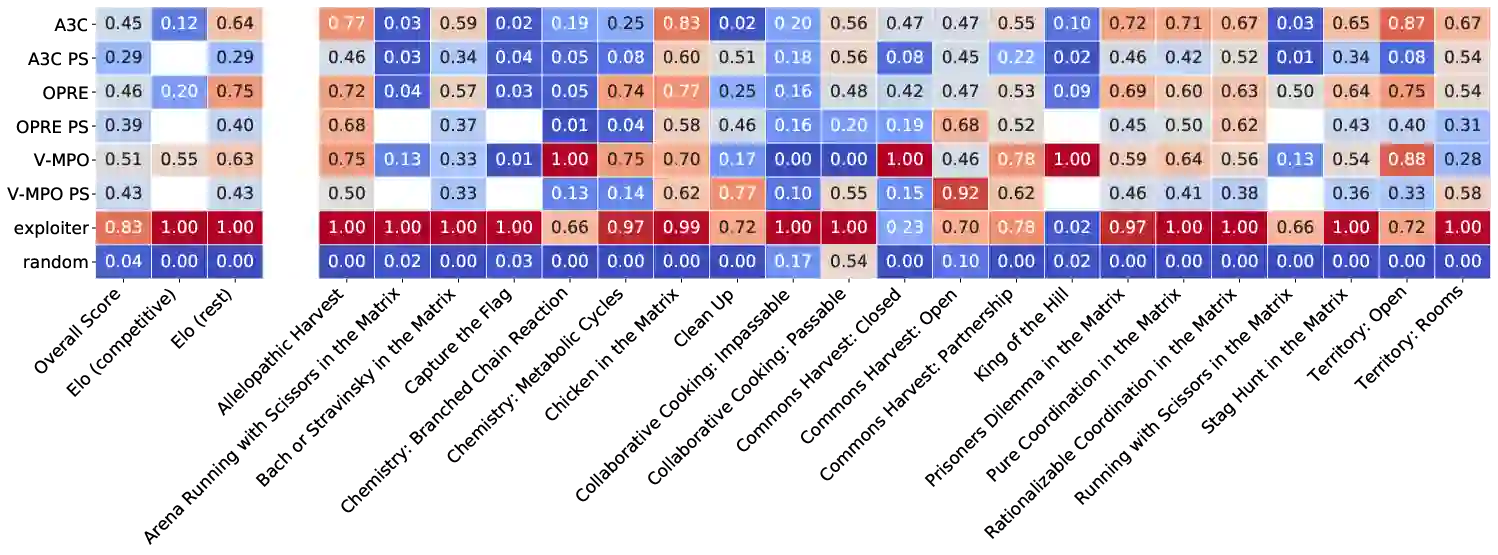
Existing evaluation suites for multi-agent reinforcement learning (MARL) do not assess generalization to novel situations as their primary objective (unlike supervised-learning benchmarks). Our contribution, Melting Pot, is a MARL evaluation suite that fills this gap, and uses reinforcement learning to reduce the human labor required to create novel test scenarios. This works because one agent's behavior constitutes (part of) another agent's environment. To demonstrate scalability, we have created over 80 unique test scenarios covering a broad range of research topics such as social dilemmas, reciprocity, resource sharing, and task partitioning. We apply these test scenarios to standard MARL training algorithms, and demonstrate how Melting Pot reveals weaknesses not apparent from training performance alone.
翻译:多试剂强化学习的现有评价套件(MARL)并不把对新情况的概括性评估作为主要目标(类似于监督学习基准 ) 。 我们的贡献是Melting Pot(Melting Pot)(MARL)评价套件,它填补了这一空白,利用强化学习来减少创造新测试假想所需的人力。 这是因为多试剂强化学习套件的行为构成( 一部分 ) 另一代理环境。 为了显示可缩放性,我们创造了80多个独特的测试情景,涉及广泛的研究课题,如社会两难、互惠、资源共享和任务分配。 我们将这些测试情景应用到标准MARL培训算法中,并展示Melting Pot如何不明显地从培训业绩中看出弱点。