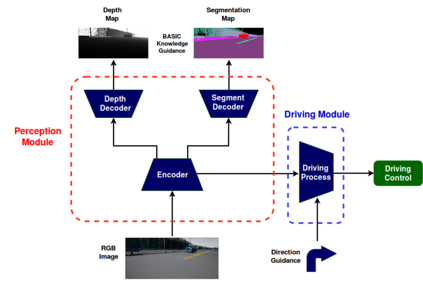
Current end-to-end deep learning driving models have two problems: (1) Poor generalization ability of unobserved driving environment when diversity of training driving dataset is limited (2) Lack of accident explanation ability when driving models don't work as expected. To tackle these two problems, rooted on the believe that knowledge of associated easy task is benificial for addressing difficult task, we proposed a new driving model which is composed of perception module for \textit{see and think} and driving module for \textit{behave}, and trained it with multi-task perception-related basic knowledge and driving knowledge stepwisely. Specifically segmentation map and depth map (pixel level understanding of images) were considered as \textit{what \& where} and \textit{how far} knowledge for tackling easier driving-related perception problems before generating final control commands for difficult driving task. The results of experiments demonstrated the effectiveness of multi-task perception knowledge for better generalization and accident explanation ability. With our method the average sucess rate of finishing most difficult navigation tasks in untrained city of CoRL test surpassed current benchmark method for 15 percent in trained weather and 20 percent in untrained weathers. Demonstration video link is: https://www.youtube.com/watch?v=N7ePnnZZwdE
翻译:当前的端到端深深学习驱动模式有两个问题:(1) 当培训驾驶数据集的多样性有限时,未观测到的驾驶环境的概括能力较差;(2) 当驾驶模型无法如预期的那样发挥作用时,缺乏事故解释能力。为了解决这两个问题,我们建议了一个新的驾驶模式,它由以下两个方面组成:(1) 当培训驾驶数据集的多样性有限时,未观测到的驾驶环境普遍化能力不足;(2) 当驾驶模型无法如预期的那样发挥作用时,缺乏事故解释能力。为了解决这两个问题,我们坚信,对相关简单任务的知识对于解决困难任务而言是容易解决的。实验结果显示,多任务感知知识对于更好地概括化和事故解释能力是有效的。我们的方法是,在未受过训练的CoRL城市完成最困难的导航任务的平均速度(像素水平对图像的理解)被视为\textit{w} 和\textit{thar} 知识对于解决与驾驶有关的认知问题是比较容易处理的。实验结果表明,多任务认知知识对于更好地概括和解释能力是有效的。在未受过训练的CRL城市测试的最困难的导航任务的平均速度速度?在15 %的天气/VSDYSUBSV=20 上,在经过训练的15的天气和20%的SDRVSUVSVSLSLSLSVSVSUTRSUTR7和20