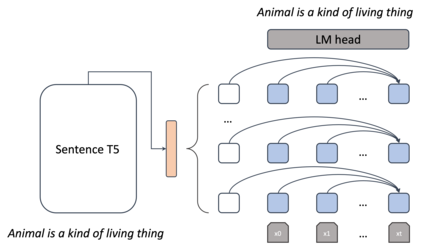
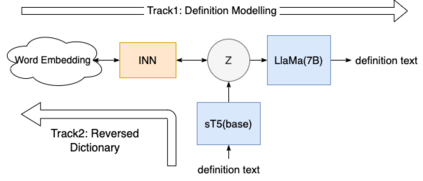
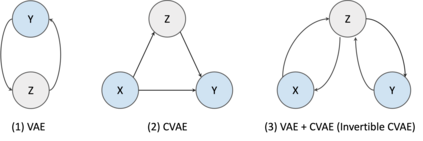
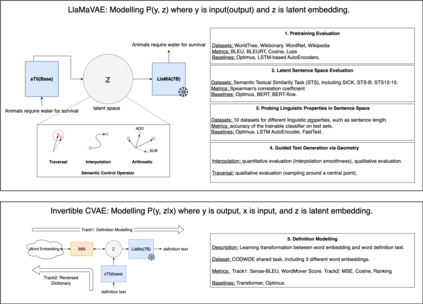
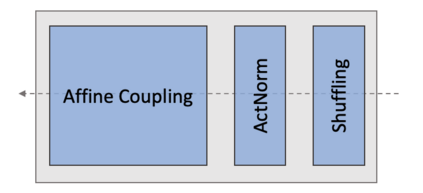
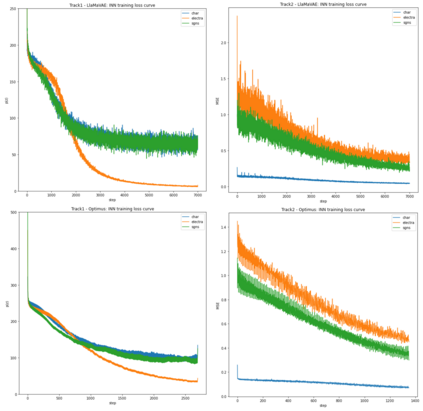
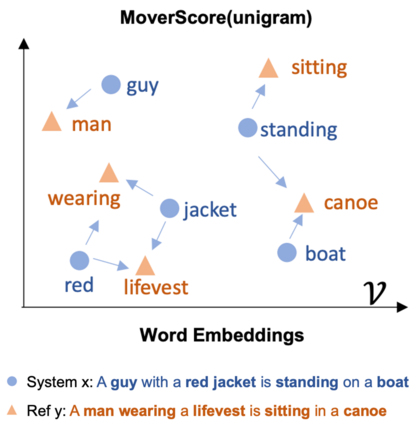
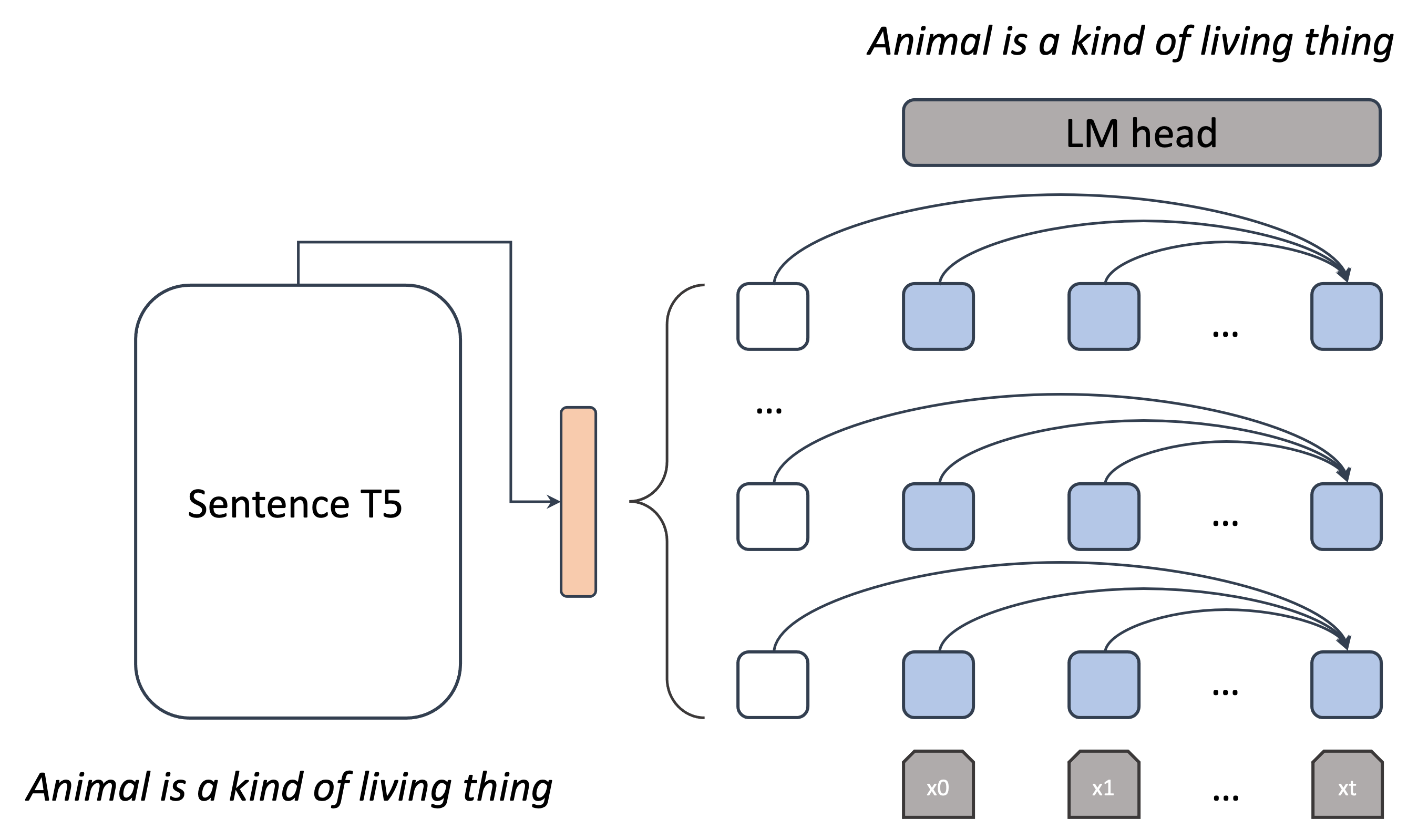
Deep generative neural networks, such as Variational AutoEncoders (VAEs), offer an opportunity to better understand and control language models from the perspective of sentence-level latent spaces. To combine the controllability of VAE latent spaces with the state-of-the-art performance of recent large language models (LLMs), we present in this work LlaMaVAE, which combines expressive encoder and decoder models (sentenceT5 and LlaMA) with a VAE architecture, aiming to provide better text generation control to LLMs. In addition, to conditionally guide the VAE generation, we investigate a new approach based on flow-based invertible neural networks (INNs) named Invertible CVAE. Experimental results reveal that LlaMaVAE can outperform the previous state-of-the-art VAE language model, Optimus, across various tasks, including language modelling, semantic textual similarity and definition modelling. Qualitative analysis on interpolation and traversal experiments also indicates an increased degree of semantic clustering and geometric consistency, which enables better generation control.
翻译:暂无翻译