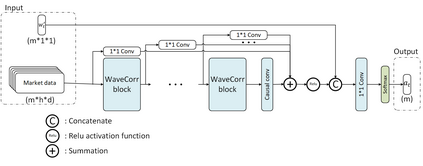
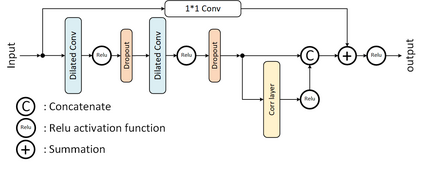
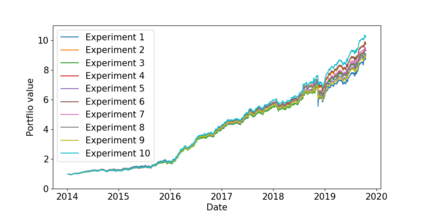
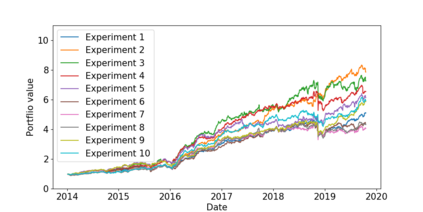
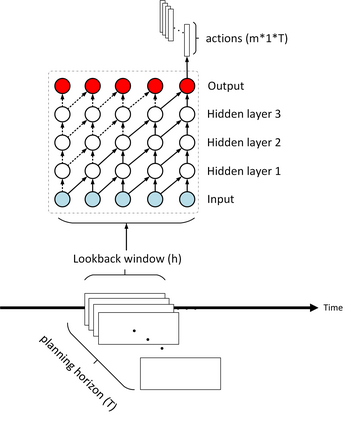
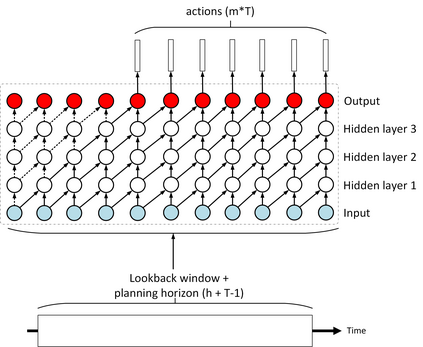
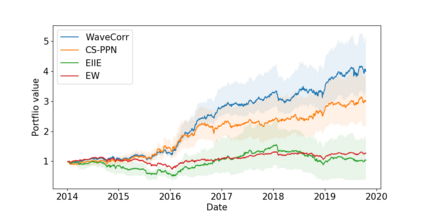
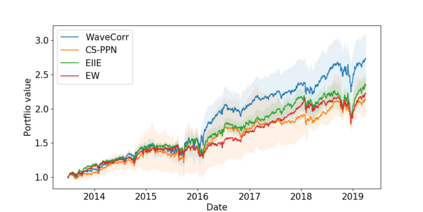
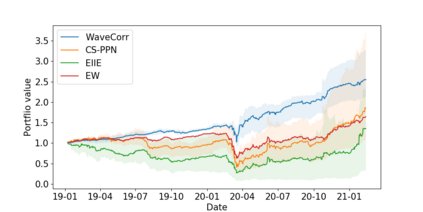
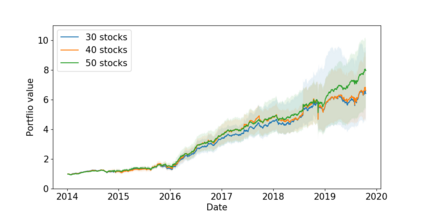
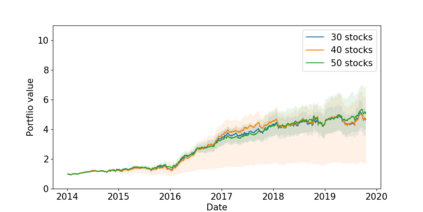
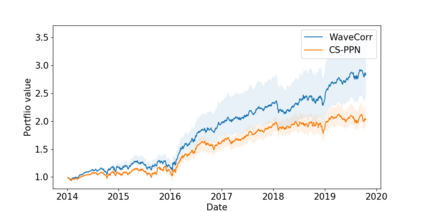
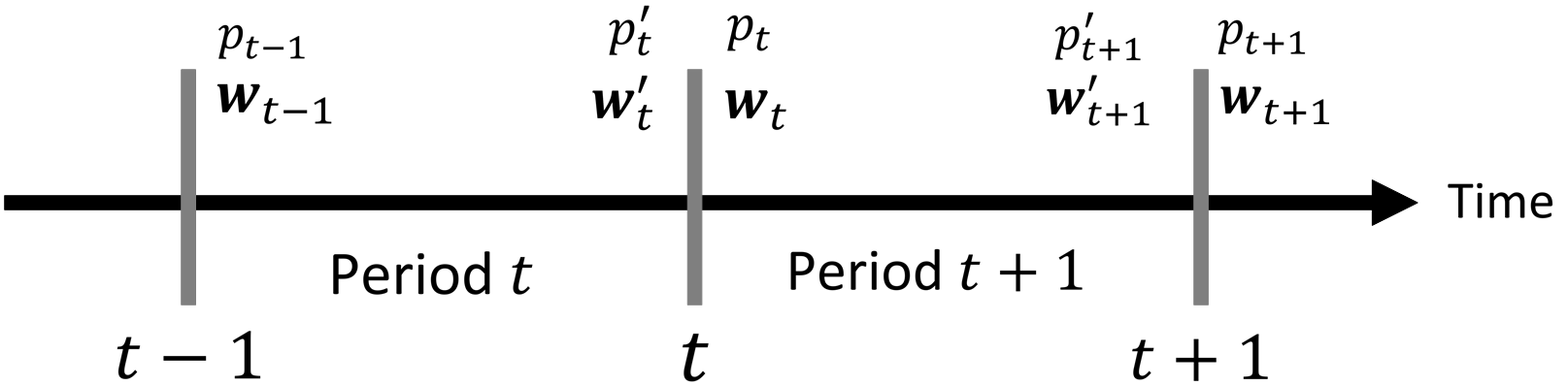
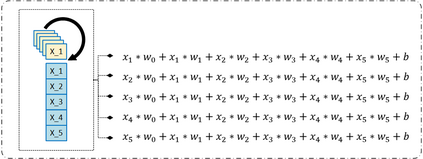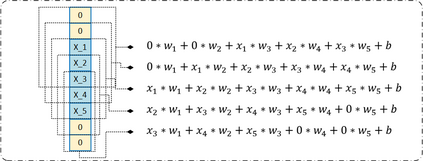The problem of portfolio management represents an important and challenging class of dynamic decision making problems, where rebalancing decisions need to be made over time with the consideration of many factors such as investors preferences, trading environments, and market conditions. In this paper, we present a new portfolio policy network architecture for deep reinforcement learning (DRL)that can exploit more effectively cross-asset dependency information and achieve better performance than state-of-the-art architectures. In particular, we introduce a new property, referred to as \textit{asset permutation invariance}, for portfolio policy networks that exploit multi-asset time series data, and design the first portfolio policy network, named WaveCorr, that preserves this invariance property when treating asset correlation information. At the core of our design is an innovative permutation invariant correlation processing layer. An extensive set of experiments are conducted using data from both Canadian (TSX) and American stock markets (S&P 500), and WaveCorr consistently outperforms other architectures with an impressive 3%-25% absolute improvement in terms of average annual return, and up to more than 200% relative improvement in average Sharpe ratio. We also measured an improvement of a factor of up to 5 in the stability of performance under random choices of initial asset ordering and weights. The stability of the network has been found as particularly valuable by our industrial partner.
翻译:证券组合管理问题是一个重要而具有挑战性的动态决策问题,需要随着时间的考虑投资者偏好、贸易环境和市场条件等许多因素来重新平衡决策。在本文件中,我们为深强化学习(DRL)提出了一个新的组合政策网络架构,可以更有效地利用跨资产依赖信息,并取得比最先进的结构更好的业绩。特别是,我们引入了一种新的财产,称为“Textit{asset 变异性”),用于利用多资产时间序列数据的投资组合政策网络,并设计了第一个组合政策网络,名为“WaveCorr”,在处理资产相关性信息时保留了这种变异性财产。我们设计的核心是创新的变异性相关处理层。我们利用加拿大(TSX)和美国股票市场(S & P 500)的数据进行了广泛的实验,WaveCorr始终优于其他结构,平均年回报率为3%-25%的绝对改善,以及平均资产回报率超过200%的投资组合政策网络相对改善幅度。我们发现,在平均资产稳定度方面,在初步稳定度上,我们根据资产稳定度的概率系数进行了5次的改进。