
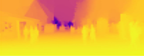
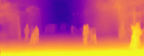
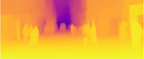
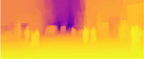
While convolutional neural networks have shown a tremendous impact on various computer vision tasks, they generally demonstrate limitations in explicitly modeling long-range dependencies due to the intrinsic locality of the convolution operation. Initially designed for natural language processing tasks, Transformers have emerged as alternative architectures with innate global self-attention mechanisms to capture long-range dependencies. In this paper, we propose TransDepth, an architecture that benefits from both convolutional neural networks and transformers. To avoid the network losing its ability to capture local-level details due to the adoption of transformers, we propose a novel decoder that employs attention mechanisms based on gates. Notably, this is the first paper that applies transformers to pixel-wise prediction problems involving continuous labels (i.e., monocular depth prediction and surface normal estimation). Extensive experiments demonstrate that the proposed TransDepth achieves state-of-the-art performance on three challenging datasets. Our code is available at: https://github.com/ygjwd12345/TransDepth.
翻译:虽然共生神经网络对各种计算机视觉任务产生了巨大影响,但一般而言,由于演化行动的内在位置,这些网络在明确模拟远距离依赖性方面存在局限性,因为演化行动的内在位置,这些网络为自然语言处理任务设计,这些变异器已成为替代结构,具有固有的全球自留机制,以捕捉长距离依赖性。在本文中,我们提议TransDepeh,这是一个既得益于共生神经网络,又受益于变异器的建筑。为了避免由于采用变异器,网络丧失捕捉当地一级细节的能力,我们提议采用基于门的注意机制来开发新的脱coder。值得注意的是,这是将变异器应用于涉及连续标签(即单眼深度预测和表面正常估计)的像素预测问题的第一份论文。广泛的实验表明,拟议的TransDepteph在三个具有挑战性的数据集上都实现了状态的性能。我们的代码可以在https://github.com/ygjwd12345/TranstyDepteph上查阅。















































































































相关内容

Source: Apple - iOS 8



