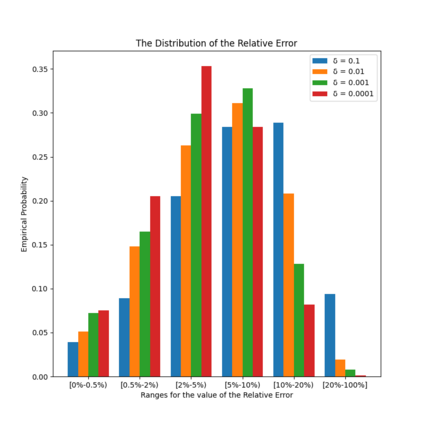
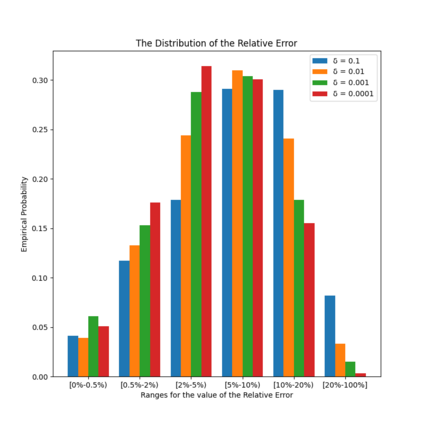
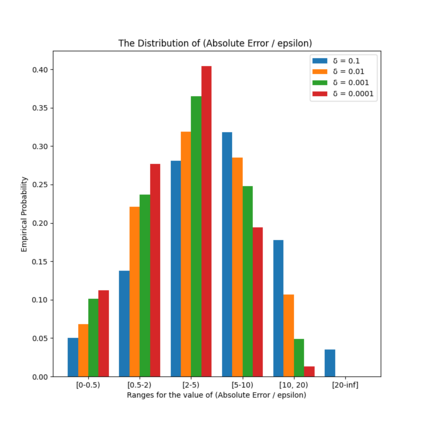
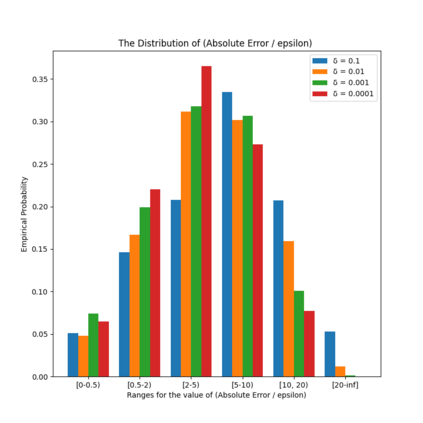
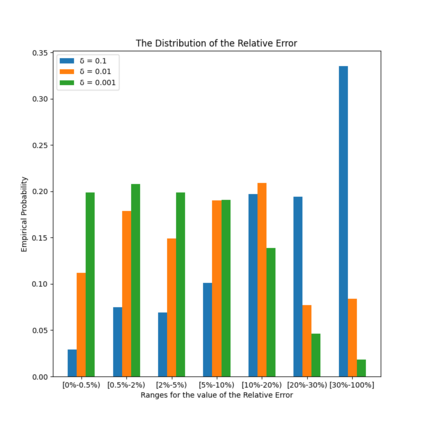
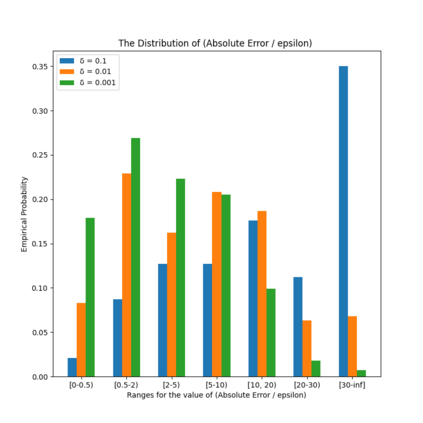
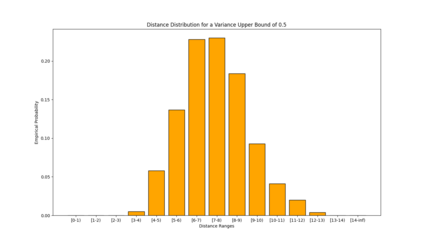
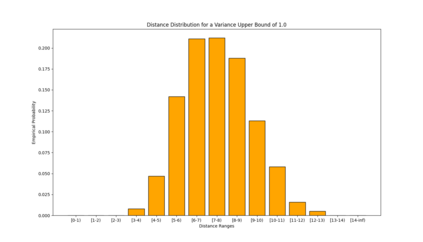
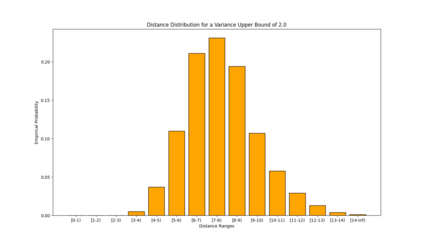
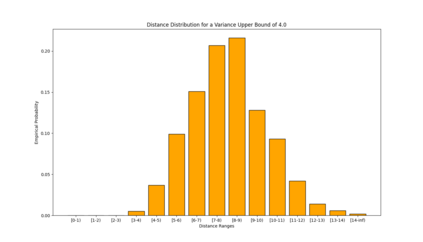
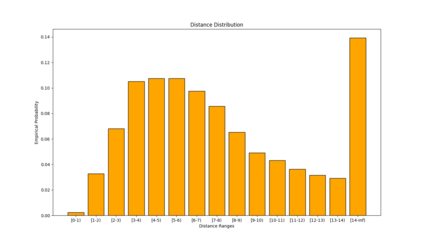
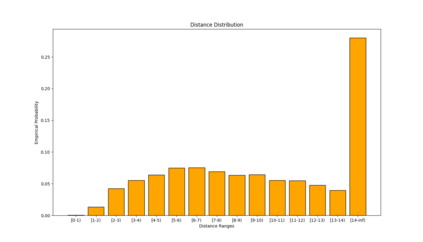
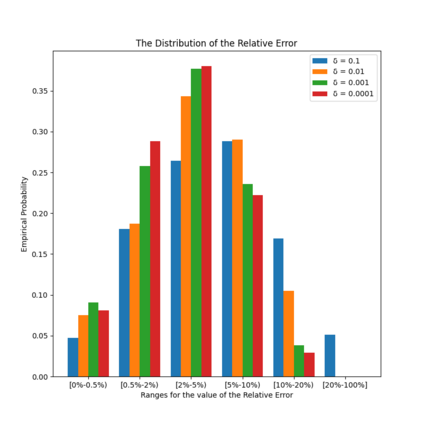
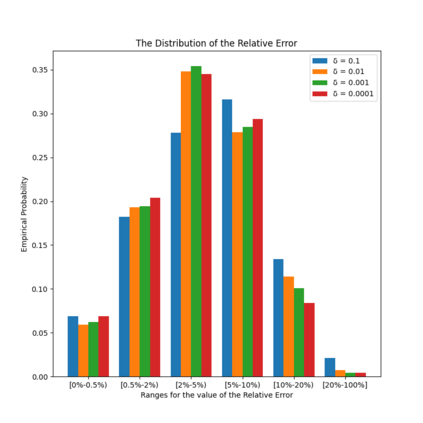
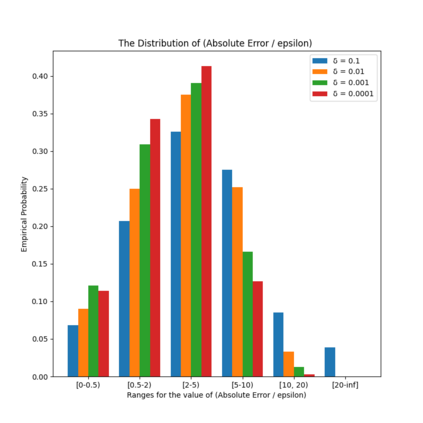
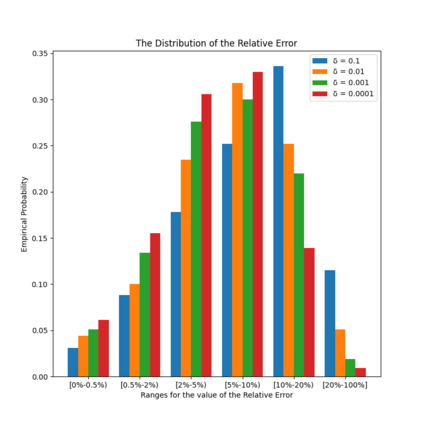
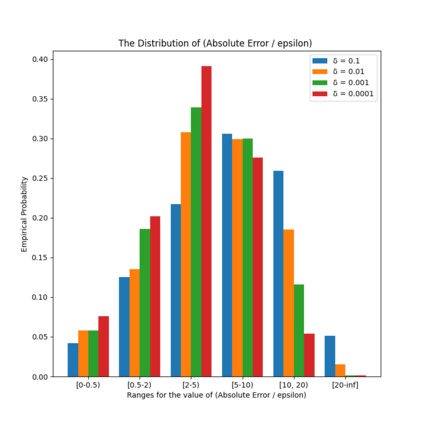
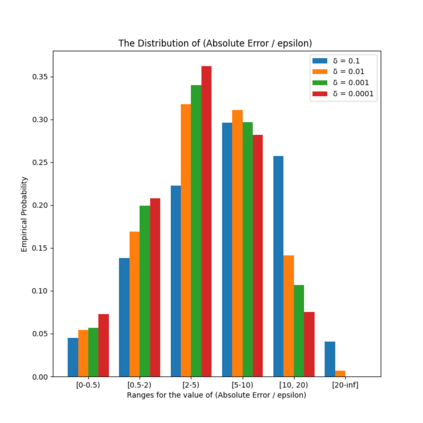
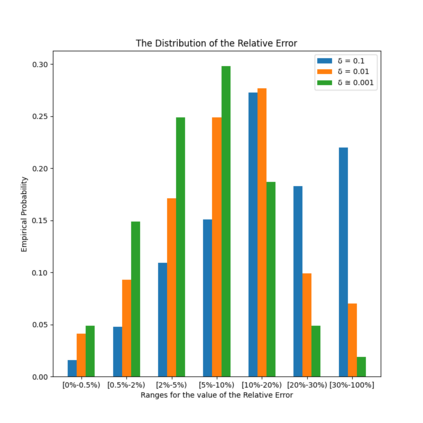
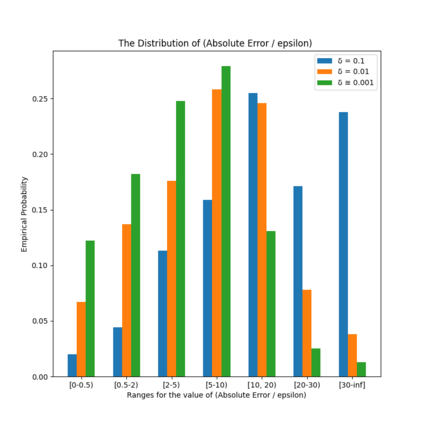
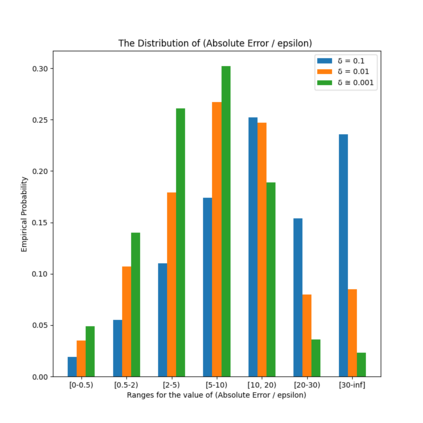
Similarity functions measure how comparable pairs of elements are, and play a key role in a wide variety of applications, e.g., Clustering problems and considerations of Individual Fairness. However, access to an accurate similarity function should not always be considered guaranteed. Specifically, when the elements to be compared are produced by different distributions, or in other words belong to different ``demographic'' groups, knowledge of their true similarity might be very difficult to obtain. In this work, we present a sampling framework that learns these across-groups similarity functions, using only a limited amount of experts' feedback. We show analytical results with rigorous bounds, and empirically validate our algorithms via a large suite of experiments.
翻译:类似功能衡量各种元素的相似性,并在多种应用中发挥关键作用,例如,集中问题和个人公平考虑。然而,获取准确相似性功能的机会不一定总能得到保证。具体地说,当要比较的要素是由不同分布产生的,或换句话说,属于不同的“人口”群体时,要了解这些元素的真正相似性可能非常困难。在这项工作中,我们提出了一个抽样框架,以学习这些跨群体相似性功能,只使用有限的专家反馈。我们展示了严格限定的分析结果,并通过大量实验从经验上验证我们的算法。