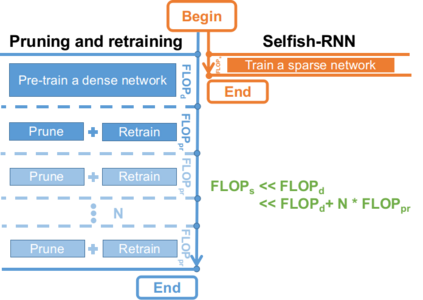
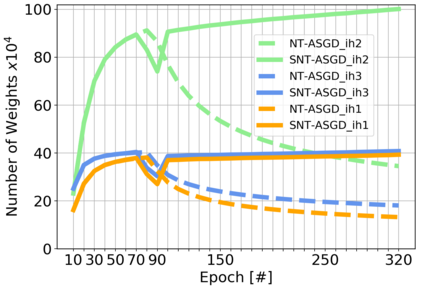
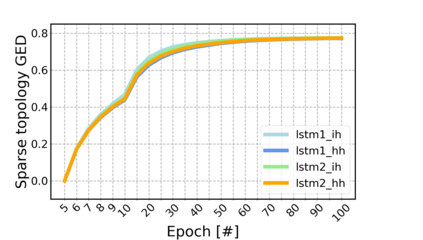
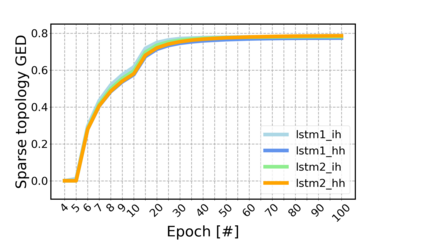
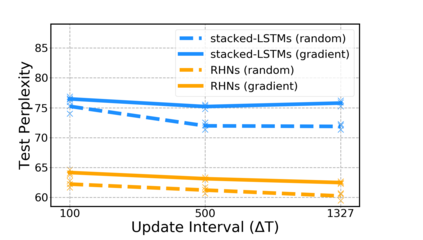
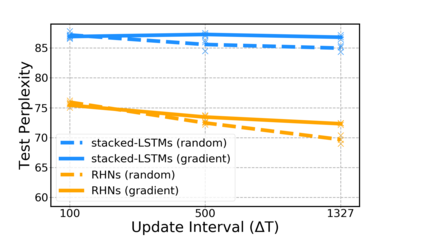
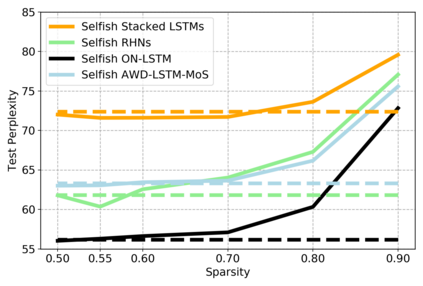
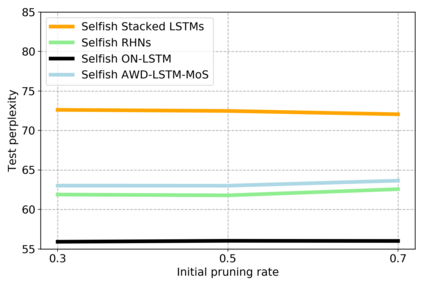
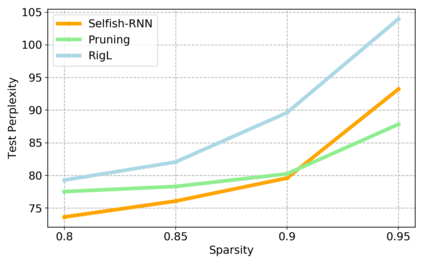
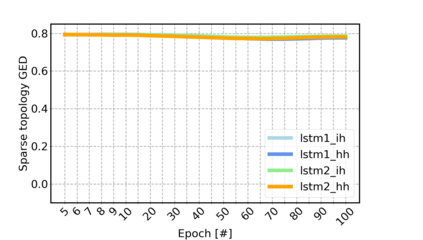
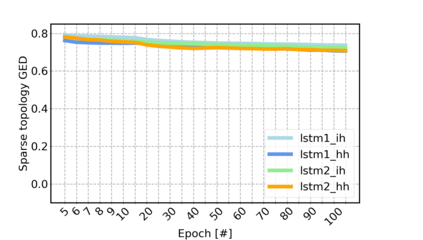
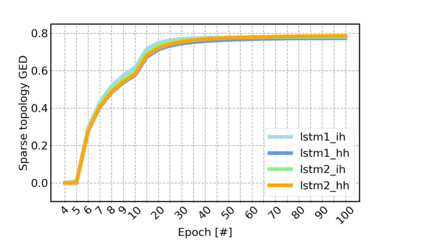
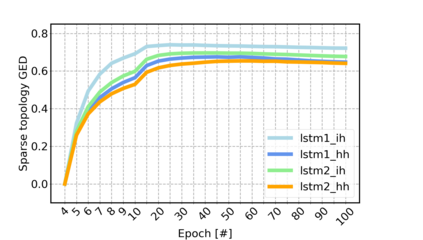
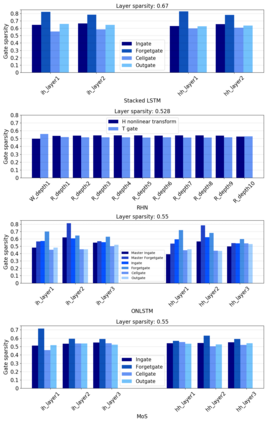
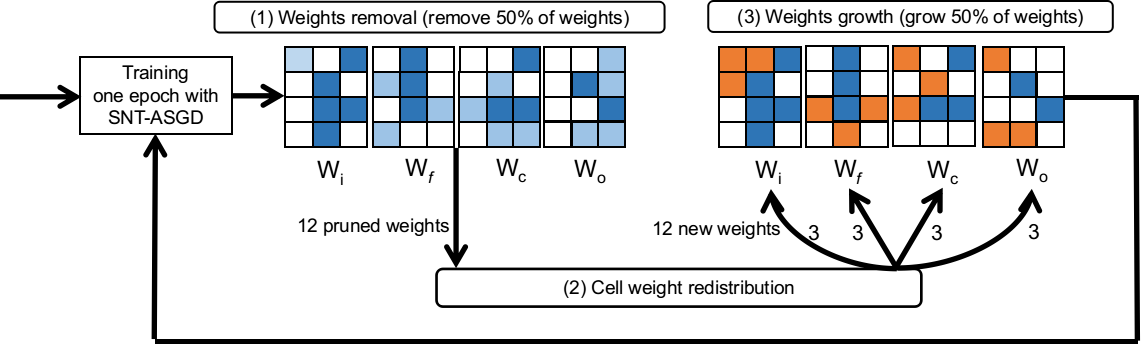Sparse neural networks have been widely applied to reduce the necessary resource requirements to train and deploy over-parameterized deep neural networks. For inference acceleration, methods that induce sparsity from a pre-trained dense network (dense-to-sparse) work effectively. Recently, dynamic sparse training (DST) has been proposed to train sparse neural networks without pre-training a dense network (sparse-to-sparse), so that the training process can also be accelerated. However, previous sparse-to-sparse methods mainly focus on Multilayer Perceptron Networks (MLPs) and Convolutional Neural Networks (CNNs), failing to match the performance of dense-to-sparse methods in Recurrent Neural Networks (RNNs) setting. In this paper, we propose an approach to train sparse RNNs with a fixed parameter count in one single run, without compromising performance. During training, we allow RNN layers to have a non-uniform redistribution across cell gates for a better regularization. Further, we introduce SNT-ASGD, a variant of the averaged stochastic gradient optimizer, which significantly improves the performance of all sparse training methods for RNNs. Using these strategies, we achieve state-of-the-art sparse training results with various types of RNNs on Penn TreeBank and Wikitext-2 datasets.
翻译:为了降低培训和部署超临界深度神经网络的必要资源需求,广泛应用了松散的神经网络,以减少培训和部署超临界深度神经网络的必要资源需求。为了加速推论,一些方法能够有效地吸引受过事先训练的密集网络(从重到粗)的广度。最近,提出了动态稀薄的培训(DST),用于培训稀薄的神经网络,而无需对密集网络(从粗到粗)进行预培训,从而也可以加快培训进程。然而,以往的稀薄到稀薄的方法主要侧重于多层 Percepron网络和神经网络,未能在常规神经网络设置中与密集到粗度的方法相匹配。在本文件中,我们提出了一种方法,在不损及业绩的前提下对稀薄的神经网络网络进行固定参数计数培训。在培训期间,我们允许RNNT在细胞大门进行非统一再分配,以更好地规范化。此外,我们引入了SNT-ASGD, 普通至神经网络网络(CNNN)网络(NNS)的变异性方法,在常规神经网络(RNNNS-NS-NT)的深度培训中,我们利用这些不固定的模小的模模模模模模模版的模范优化方法,大大地改进了各种标准,从而大大地改进了各种的NNNNNNNT培训结果。