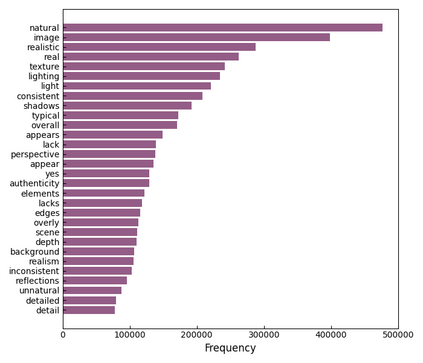
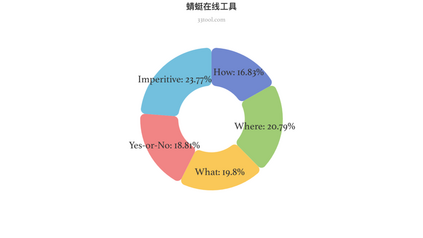
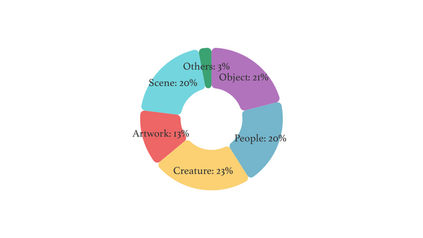
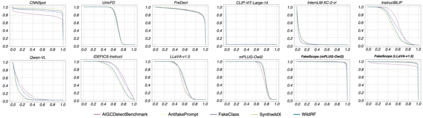
The rapid and unrestrained advancement of generative artificial intelligence (AI) presents a double-edged sword: while enabling unprecedented creativity, it also facilitates the generation of highly convincing deceptive content, undermining societal trust. As image generation techniques become increasingly sophisticated, detecting synthetic images is no longer just a binary task: it necessitates interpretable, context-aware methodologies that enhance trustworthiness and transparency. However, existing detection models primarily focus on classification, offering limited explanatory insights into image authenticity. In this work, we propose FakeScope, an expert multimodal model (LMM) tailored for AI-generated image forensics, which not only identifies AI-synthetic images with high accuracy but also provides rich, interpretable, and query-driven forensic insights. We first construct FakeChain dataset that contains linguistic authenticity reasoning based on visual trace evidence, developed through a novel human-machine collaborative framework. Building upon it, we further present FakeInstruct, the largest multimodal instruction tuning dataset containing 2 million visual instructions tailored to enhance forensic awareness in LMMs. FakeScope achieves state-of-the-art performance in both closed-ended and open-ended forensic scenarios. It can distinguish synthetic images with high accuracy while offering coherent and insightful explanations, free-form discussions on fine-grained forgery attributes, and actionable enhancement strategies. Notably, despite being trained exclusively on qualitative hard labels, FakeScope demonstrates remarkable zero-shot quantitative capability on detection, enabled by our proposed token-based probability estimation strategy. Furthermore, FakeScope exhibits strong generalization and in-the-wild ability, ensuring its applicability in real-world scenarios.
翻译:暂无翻译