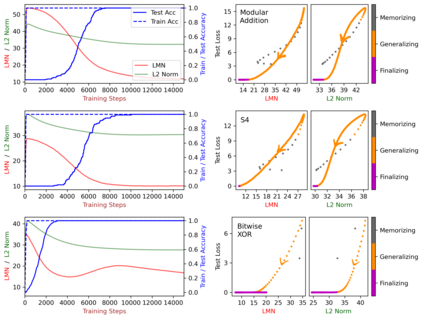
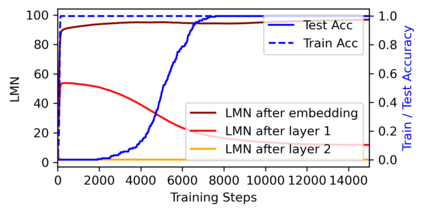
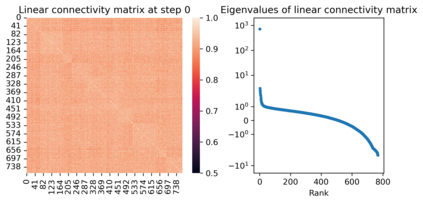
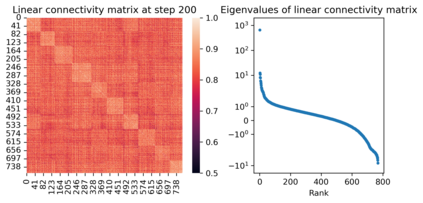
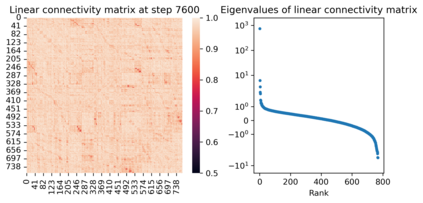
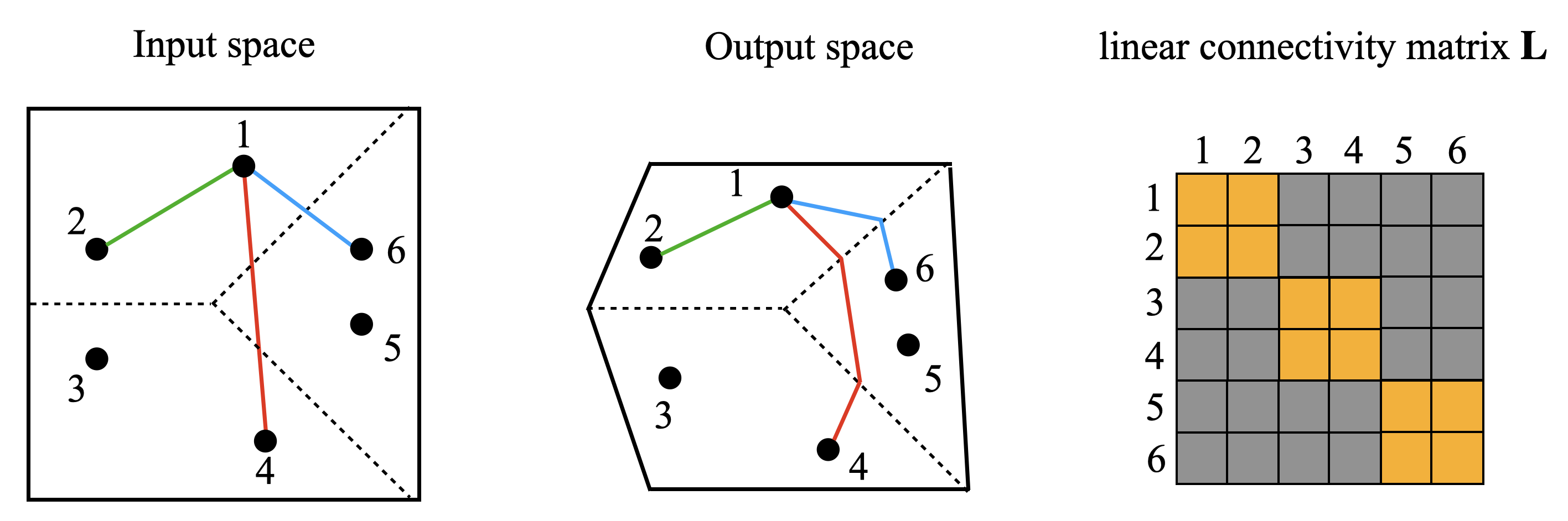
We attribute grokking, the phenomenon where generalization is much delayed after memorization, to compression. To do so, we define linear mapping number (LMN) to measure network complexity, which is a generalized version of linear region number for ReLU networks. LMN can nicely characterize neural network compression before generalization. Although the $L_2$ norm has been a popular choice for characterizing model complexity, we argue in favor of LMN for a number of reasons: (1) LMN can be naturally interpreted as information/computation, while $L_2$ cannot. (2) In the compression phase, LMN has linear relations with test losses, while $L_2$ is correlated with test losses in a complicated nonlinear way. (3) LMN also reveals an intriguing phenomenon of the XOR network switching between two generalization solutions, while $L_2$ does not. Besides explaining grokking, we argue that LMN is a promising candidate as the neural network version of the Kolmogorov complexity since it explicitly considers local or conditioned linear computations aligned with the nature of modern artificial neural networks.
翻译:暂无翻译