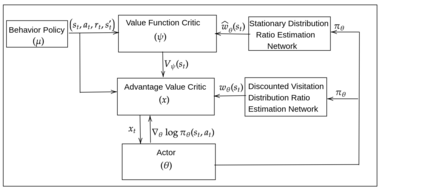
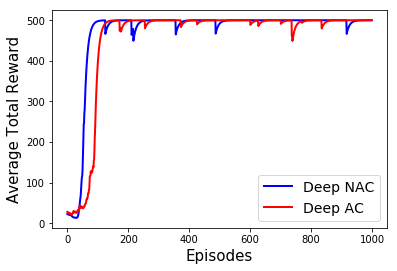
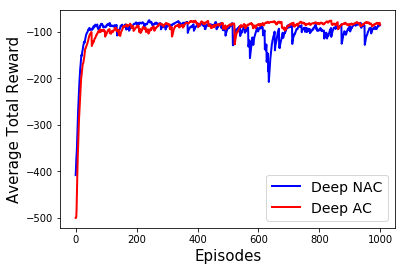
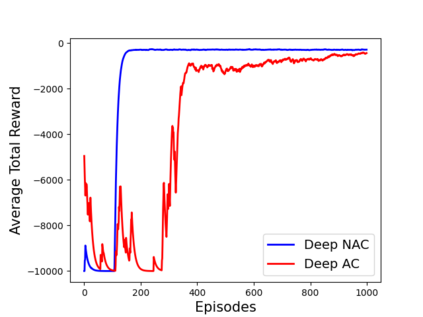
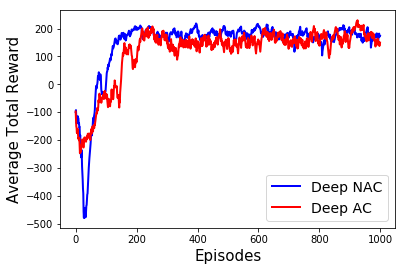
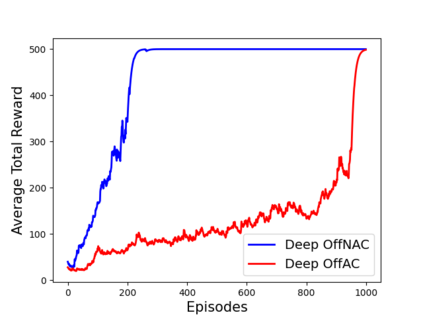
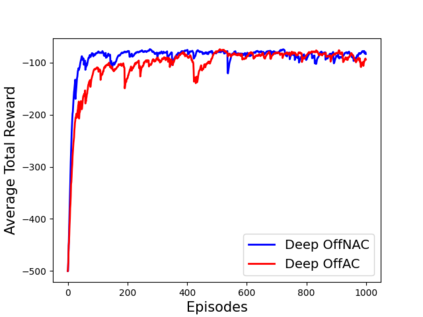
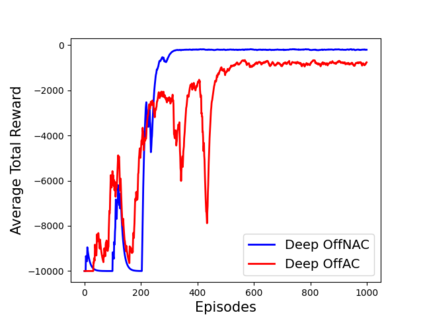
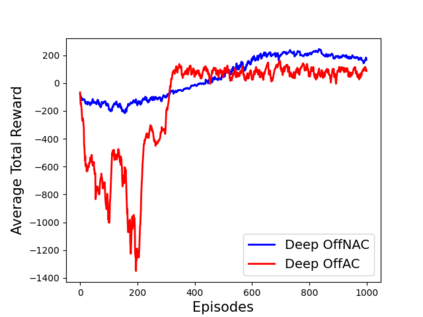
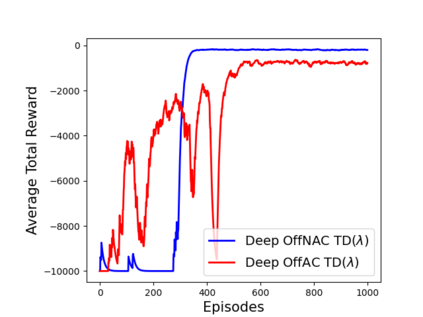
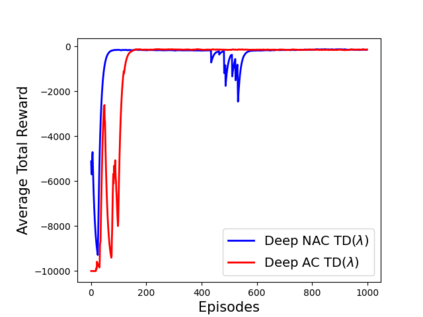
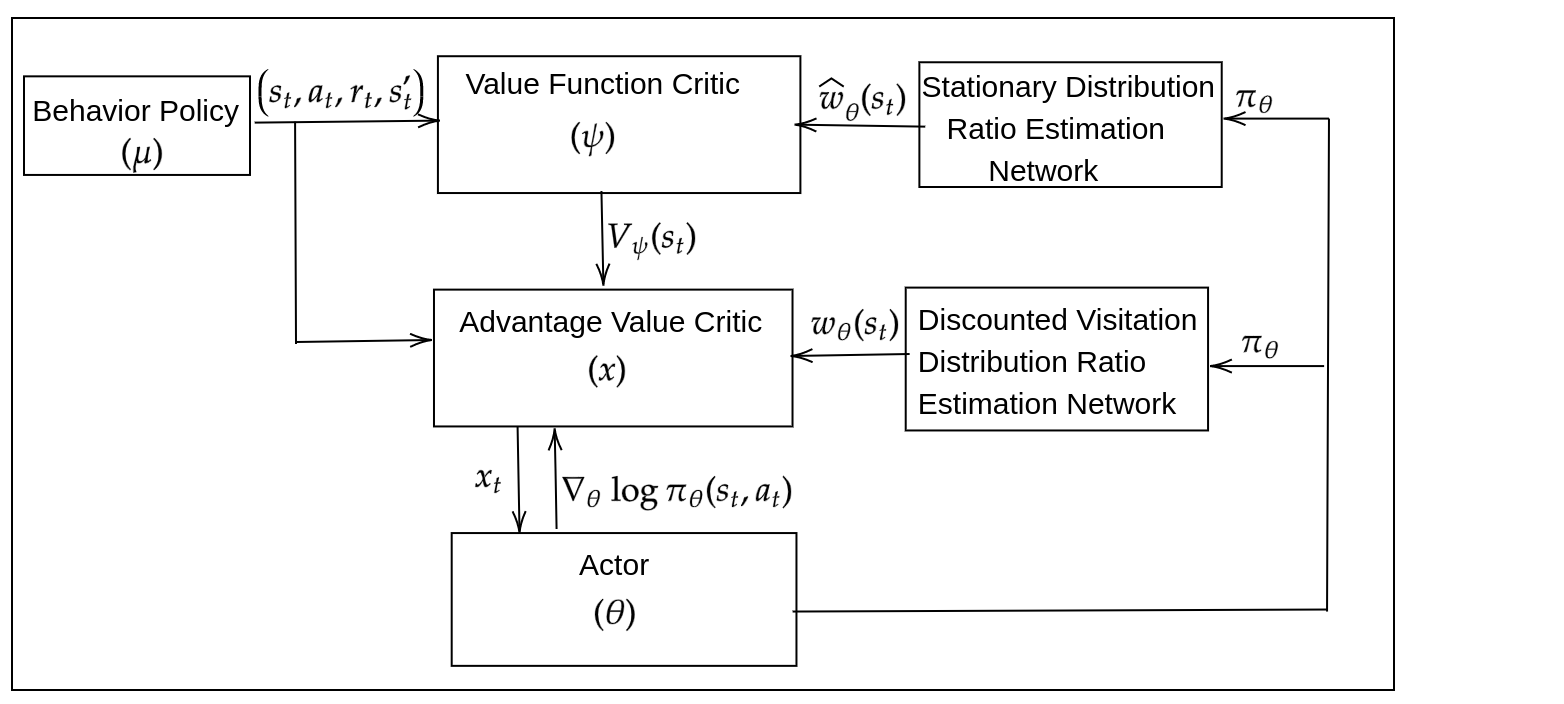
Learning optimal behavior from existing data is one of the most important problems in Reinforcement Learning (RL). This is known as "off-policy control" in RL where an agent's objective is to compute an optimal policy based on the data obtained from the given policy (known as the behavior policy). As the optimal policy can be very different from the behavior policy, learning optimal behavior is very hard in the "off-policy" setting compared to the "on-policy" setting where new data from the policy updates will be utilized in learning. This work proposes an off-policy natural actor-critic algorithm that utilizes state-action distribution correction for handling the off-policy behavior and the natural policy gradient for sample efficiency. The existing natural gradient-based actor-critic algorithms with convergence guarantees require fixed features for approximating both policy and value functions. This often leads to sub-optimal learning in many RL applications. On the other hand, our proposed algorithm utilizes compatible features that enable one to use arbitrary neural networks to approximate the policy and the value function and guarantee convergence to a locally optimal policy. We illustrate the benefit of the proposed off-policy natural gradient algorithm by comparing it with the vanilla gradient actor-critic algorithm on benchmark RL tasks.
翻译:从现有数据中学习最佳行为是加强学习中最重要的问题之一。 这项工作在《 强化学习》中被称为“ 脱政策控制”, 代理商的目标是根据从特定政策获得的数据( 称为行为政策) 计算最佳政策。 由于最佳政策可能与行为政策大不相同, 与“ 脱政策” 设置相比, “ 脱政策” 设置学习最佳行为非常困难, 政策更新中的新数据将被用于学习。 这项工作建议采用一种非政策性自然行为者- 批评算法, 利用国家行动分配校正处理离政策行为和自然政策梯度, 以抽样效率为目的。 现有的基于梯度的行为者- 批评算法, 与趋同的保证要求与政策和价值功能相近的固定特征。 这往往导致在许多 RL 应用程序中进行次优化学习。 另一方面, 我们提议的算法使用兼容的特性, 使得人们能够使用任意的神经网络来比较政策和价值功能, 并保证与当地最佳政策趋同。 我们用拟议的越轨式矩阵来比较拟议的越轨性趋势。