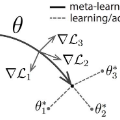
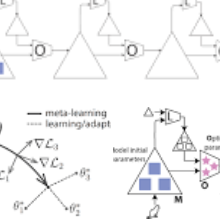
Federated Learning (FL) refers to learning a high quality global model based on decentralized data storage, without ever copying the raw data. A natural scenario arises with data created on mobile phones by the activity of their users. Given the typical data heterogeneity in such situations, it is natural to ask how can the global model be personalized for every such device, individually. In this work, we point out that the setting of Model Agnostic Meta Learning (MAML), where one optimizes for a fast, gradient-based, few-shot adaptation to a heterogeneous distribution of tasks, has a number of similarities with the objective of personalization for FL. We present FL as a natural source of practical applications for MAML algorithms, and make the following observations. 1) The popular FL algorithm, Federated Averaging, can be interpreted as a meta learning algorithm. 2) Careful fine-tuning can yield a global model with higher accuracy, which is at the same time easier to personalize. However, solely optimizing for the global model accuracy yields a weaker personalization result. 3) A model trained using a standard datacenter optimization method is much harder to personalize, compared to one trained using Federated Averaging, supporting the first claim. These results raise new questions for FL, MAML, and broader ML research.
翻译:联邦学习联合会(FL) 指的是学习基于分散数据存储的高质量全球模型,而无需复制原始数据。自然的情况是,移动电话用户活动产生的数据具有一些相似之处。鉴于这类情况下典型的数据差异性,很自然地会问全球模型如何针对每个这类设备个人化。在这项工作中,我们指出,模型Agnistic Meta Learning(MAML)的设置可以产生一个具有更高准确性的全球模型,这种模型可以优化快速、基于梯度的微小的适应,以适应不同的任务分布,与FL的个性化目标有一些相似之处。我们提出FL作为MAML算法实际应用的自然来源,并提出以下意见:(1) 流行的FL算法,即Fed Avering Avering,可以被解释为一种元性学习算法。(2) 仔细的微调可以产生一种具有更高准确性的全球模型,而个人化也比较容易。然而,仅仅优化全球模型的精确性会降低个性化结果。(3) 使用标准数据中心优化方法培训的模型,很难实现个人化,比FML更广义的研究结果。