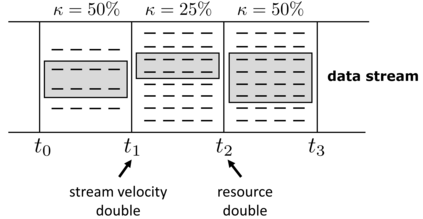
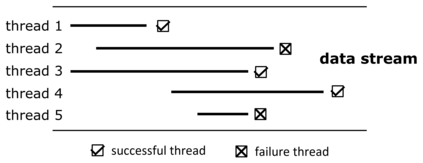
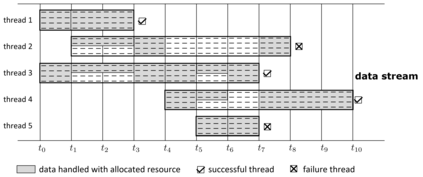
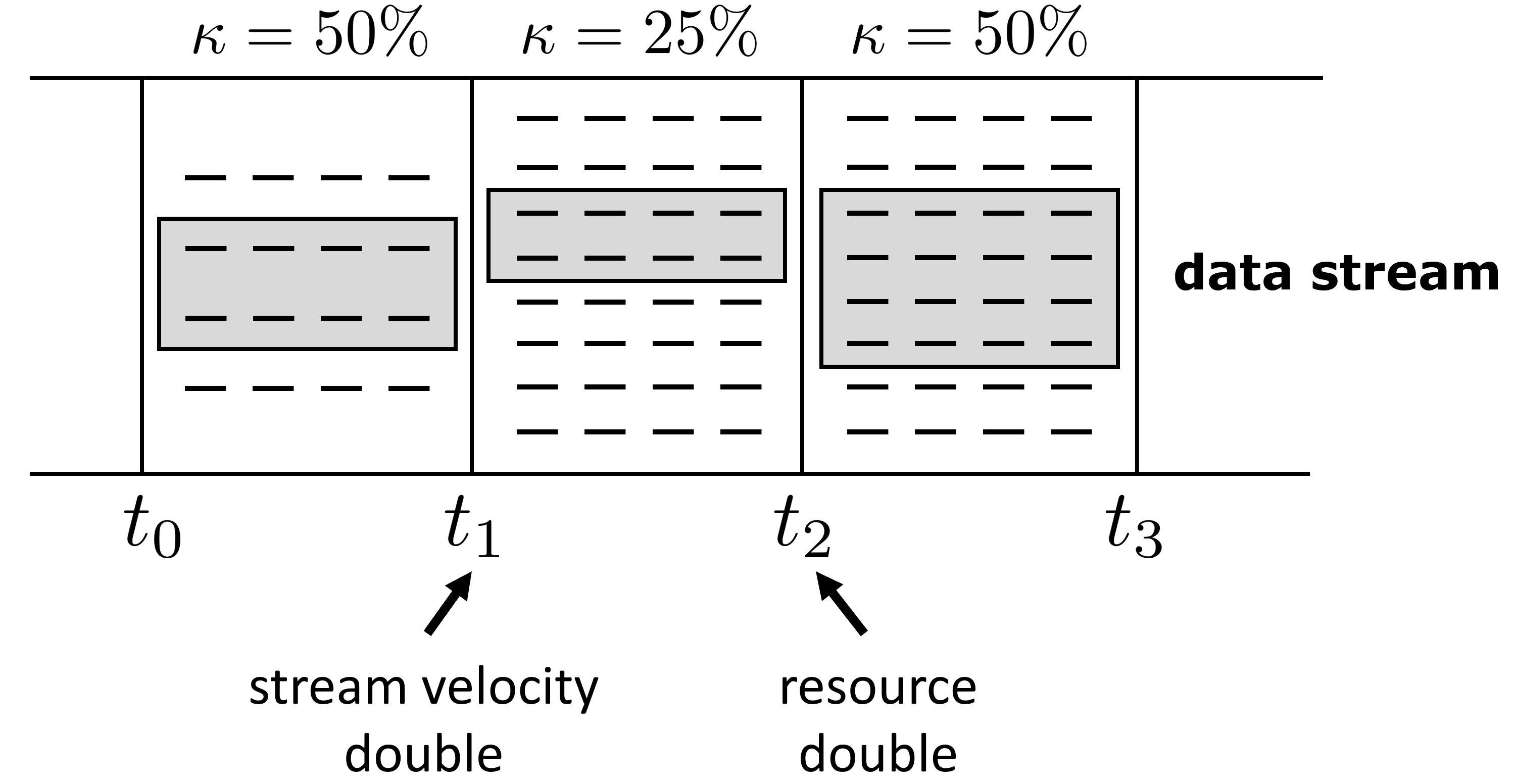
Data in many real-world applications are often accumulated over time, like a stream. In contrast to conventional machine learning studies that focus on learning from a given training data set, learning from data streams cannot ignore the fact that the incoming data stream can be potentially endless with overwhelming size and unknown changes, and it is impractical to assume to have sufficient computational/storage resource such that all received data can be handled in time. Thus, the generalization performance of learning from data streams depends not only on how many data have been received, but also on how many data can be well exploited timely, with resource and rapidity concerns, in addition to the ability of learning algorithm and complexity of the problem. For this purpose, in this article we introduce the notion of machine learning throughput, define Stream Efficient Learning and present a preliminary theoretical framework.
翻译:暂无翻译