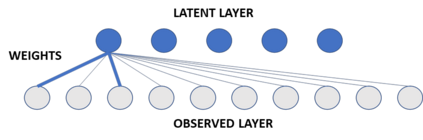
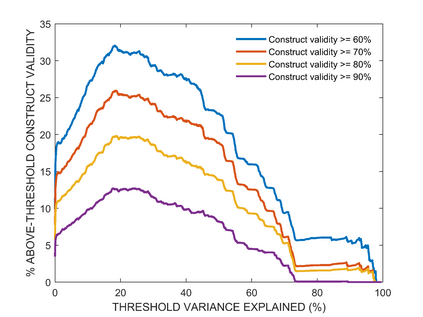
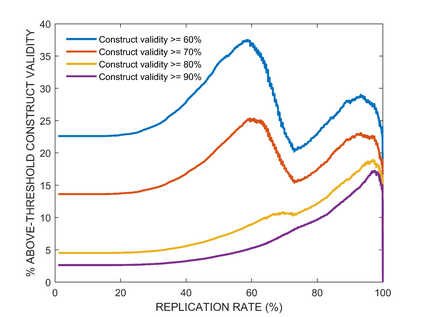
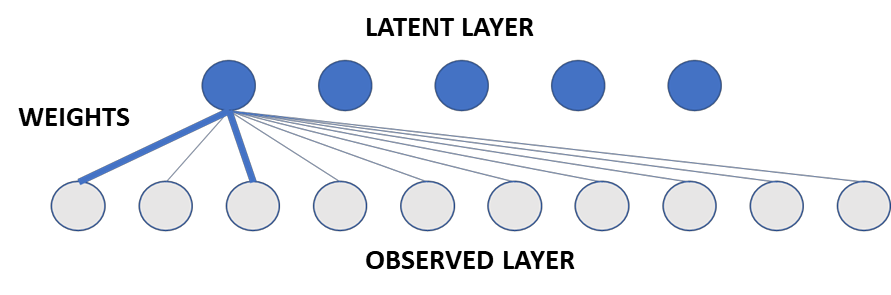
In many scientific disciplines, the features of interest cannot be observed directly, so must instead be inferred from observed behaviour. Latent variable analyses are increasingly employed to systematise these inferences, and Principal Components Analysis (PCA) is perhaps the simplest and most popular of these methods. Here, we examine how the assumptions that we are prepared to entertain, about the latent variable system, mediate the likelihood that PCA-derived components will capture the true sources of variance underlying data. As expected, we find that this likelihood is excellent in the best case, and robust to empirically reasonable levels of measurement noise, but best-case performance is also: (a) not robust to violations of the method's more prominent assumptions, of linearity and orthogonality; and also (b) requires that other subtler assumptions be made, such as that the latent variables should have varying importance, and that weights relating latent variables to observed data have zero mean. Neither variance explained, nor replication in independent samples, could reliably predict which (if any) PCA-derived components will capture true sources of variance in data. We conclude by describing a procedure to fit these inferences more directly to empirical data, and use it to find that components derived via PCA from two different empirical neuropsychological datasets, are less likely to have meaningful referents in the brain than we hoped.
翻译:暂无翻译