
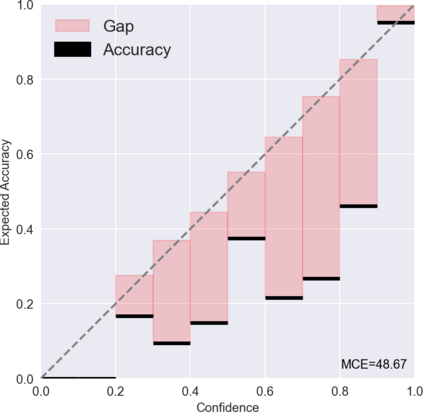
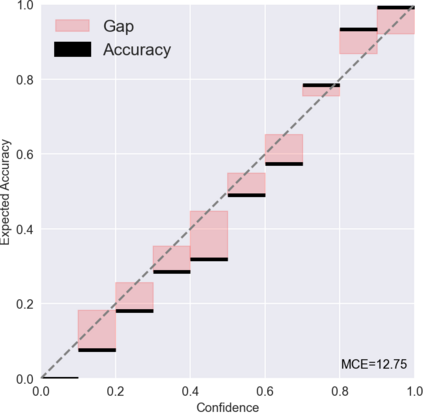
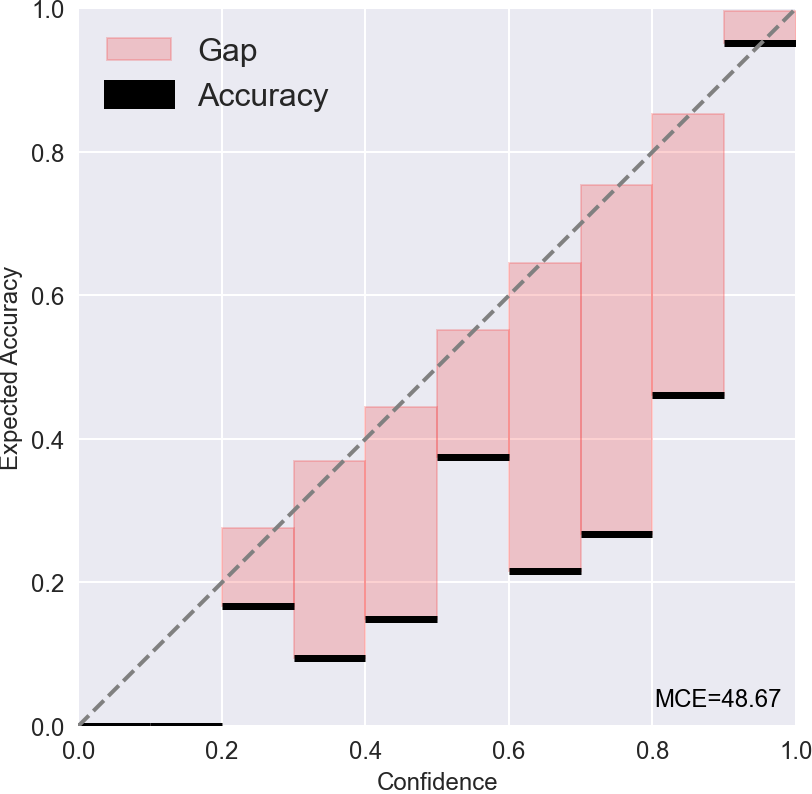
Most existing methods of Out-of-Domain (OOD) intent classification rely on extensive auxiliary OOD corpora or specific training paradigms. However, they are underdeveloped in the underlying principle that the models should have differentiated confidence in In- and Out-of-domain intent. In this work, we shed light on the fundamental cause of model overconfidence on OOD and demonstrate that calibrated subnetworks can be uncovered by pruning the overparameterized model. Calibrated confidence provided by the subnetwork can better distinguish In- and Out-of-domain, which can be a benefit for almost all post hoc methods. In addition to bringing fundamental insights, we also extend the Lottery Ticket Hypothesis to open-world scenarios. We conduct extensive experiments on four real-world datasets to demonstrate our approach can establish consistent improvements compared with a suite of competitive baselines.
翻译:暂无翻译



相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


