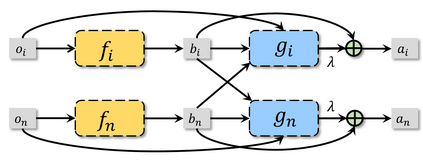
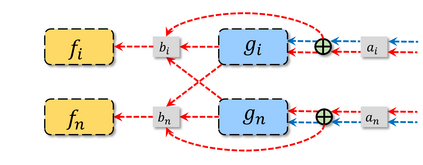
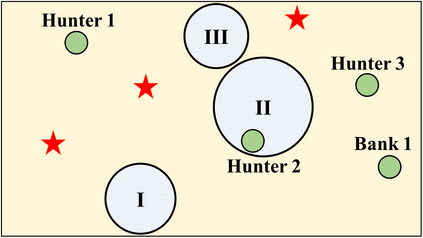
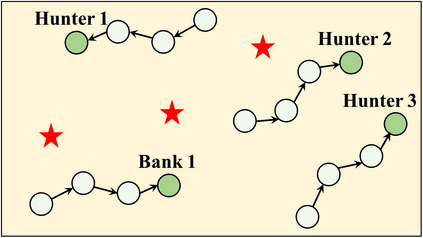
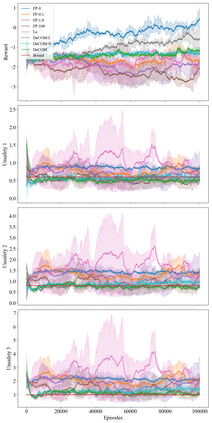
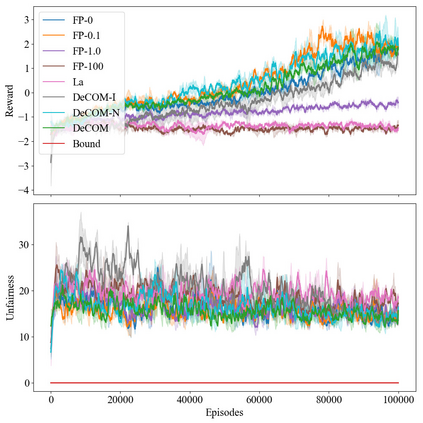
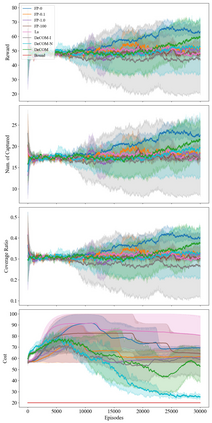
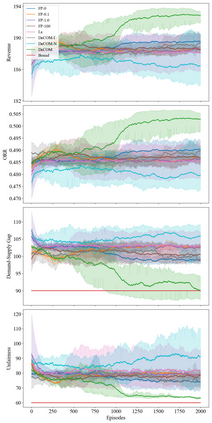
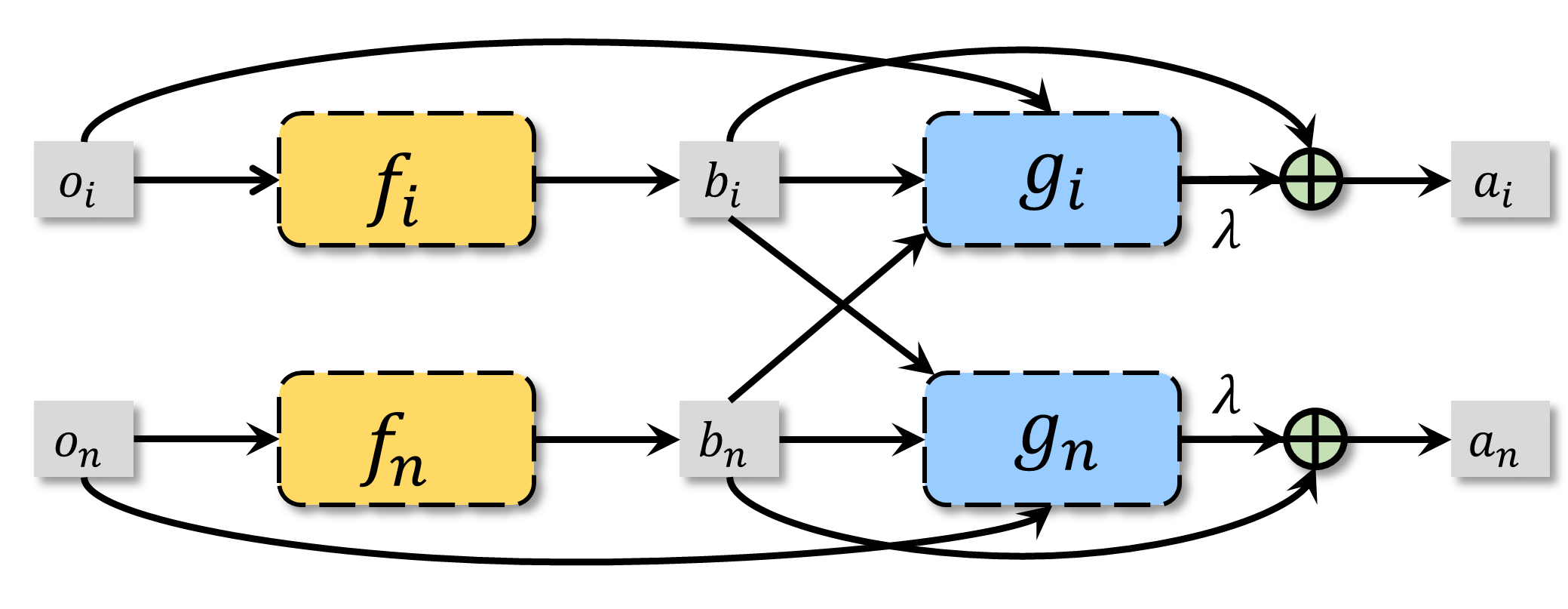
In recent years, multi-agent reinforcement learning (MARL) has presented impressive performance in various applications. However, physical limitations, budget restrictions, and many other factors usually impose \textit{constraints} on a multi-agent system (MAS), which cannot be handled by traditional MARL frameworks. Specifically, this paper focuses on constrained MASes where agents work \textit{cooperatively} to maximize the expected team-average return under various constraints on expected team-average costs, and develops a \textit{constrained cooperative MARL} framework, named DeCOM, for such MASes. In particular, DeCOM decomposes the policy of each agent into two modules, which empowers information sharing among agents to achieve better cooperation. In addition, with such modularization, the training algorithm of DeCOM separates the original constrained optimization into an unconstrained optimization on reward and a constraints satisfaction problem on costs. DeCOM then iteratively solves these problems in a computationally efficient manner, which makes DeCOM highly scalable. We also provide theoretical guarantees on the convergence of DeCOM's policy update algorithm. Finally, we validate the effectiveness of DeCOM with various types of costs in both toy and large-scale (with 500 agents) environments.
翻译:近年来,多剂加固学习(MARL)在各种应用中表现出了令人印象深刻的成绩,然而,有形限制、预算限制和许多其他因素通常对多剂系统(MAS)施加限制,这种系统不能由传统的MARL框架处理。具体地说,本文件侧重于有限的MAS,在这些系统中,代理人在预期团队平均成本的各种限制下,为最大限度地实现预期团队平均回报率,并针对此类MAS开发了一个称为DeCOM的Textit{受制约的合作MARL}框架。特别是,DeCOM将每个代理人的政策分成两个模块,授权各代理人之间分享信息,以加强合作。此外,除了这种模块化外,DeCOM的培训算法将原来的限制优化分为对奖励的不严格优化和对成本满意度的制约问题。然后,DerCOM反复地以计算效率的方式解决这些问题,使DeCOM高度可缩缩缩。我们还就DeCOM政策更新算法与大规模成本(COM)和大型代理商环境的整合提供了理论保证。最后,我们确认,除了模块化外,DCOM的效益与各种类型的公司环境。