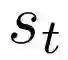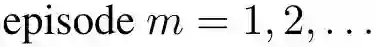In recent years, deep off-policy actor-critic algorithms have become a dominant approach to reinforcement learning for continuous control. One of the primary drivers of this improved performance is the use of pessimistic value updates to address function approximation errors, which previously led to disappointing performance. However, a direct consequence of pessimism is reduced exploration, running counter to theoretical support for the efficacy of optimism in the face of uncertainty. So which approach is best? In this work, we show that the most effective degree of optimism can vary both across tasks and over the course of learning. Inspired by this insight, we introduce a novel deep actor-critic framework, Tactical Optimistic and Pessimistic (TOP) estimation, which switches between optimistic and pessimistic value learning online. This is achieved by formulating the selection as a multi-arm bandit problem. We show in a series of continuous control tasks that TOP outperforms existing methods which rely on a fixed degree of optimism, setting a new state of the art in challenging pixel-based environments. Since our changes are simple to implement, we believe these insights can easily be incorporated into a multitude of off-policy algorithms.
翻译:近年来,深层的从政策角度出发的行为者-批评算法已成为加强学习以持续控制的主要方法。这一改进业绩的主要驱动因素之一是利用悲观价值更新来解决功能近似错误,这曾导致业绩令人失望。然而,悲观主义的直接后果是探索减少,这与面对不确定性时乐观主义效力的理论支持相悖。因此,哪种方法是最好的?在这项工作中,我们表明,最有效的乐观程度可以因任务和学习过程而不同。受这一洞察力的启发,我们引入了一个新的深层次的行为者-批评框架,即实践性乐观和悲观性(TOP)估计,这种估计在乐观和悲观价值的在线学习之间互换。这是通过将选择设计成多臂宽幅问题来实现的。我们通过一系列连续的控制任务显示,TOP超越了依赖固定的乐观程度的现有方法,在挑战像素基环境方面确定了新的艺术状态。由于我们的改革很简单,我们认为这些洞察力可以很容易地纳入多种反动算法中。