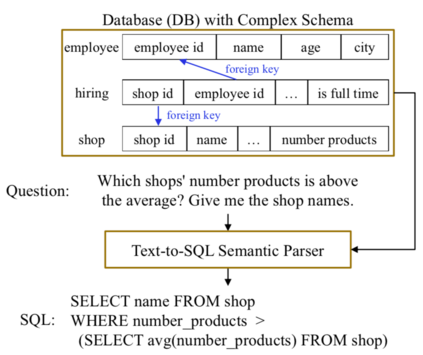
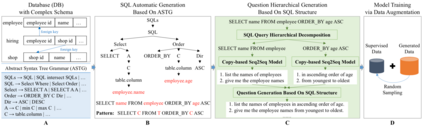
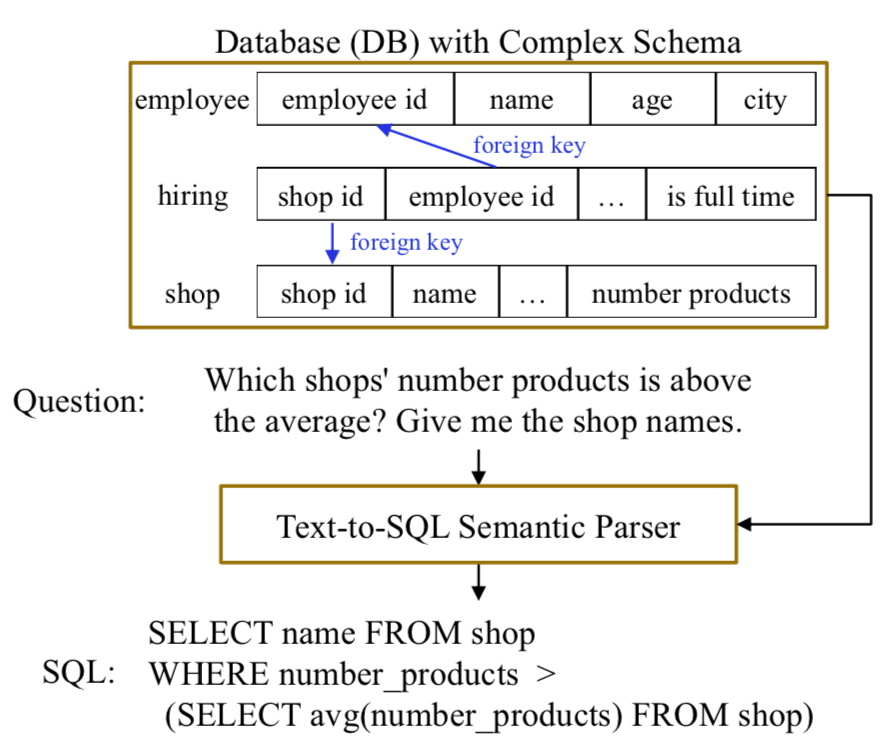
Data augmentation has attracted a lot of research attention in the deep learning era for its ability in alleviating data sparseness. The lack of data for unseen evaluation databases is exactly the major challenge for cross-domain text-to-SQL parsing. Previous works either require human intervention to guarantee the quality of generated data, or fail to handle complex SQL queries. This paper presents a simple yet effective data augmentation framework. First, given a database, we automatically produce a large amount of SQL queries based on an abstract syntax tree grammar. We require the generated queries cover at least 80% of SQL patterns in the training data for better distribution matching. Second, we propose a hierarchical SQL-to-question generation model to obtain high-quality natural language questions, which is the major contribution of this work. Experiments on three cross-domain datasets, i.e., WikiSQL and Spider in English, and DuSQL in Chinese, show that our proposed data augmentation framework can consistently improve performance over strong baselines, and in particular the hierarchical generation model is the key for the improvement.
翻译:在深层次的学习时代,数据扩增因其在减轻数据稀少方面的能力而吸引了大量的研究关注。 缺乏用于隐性评估数据库的数据正是跨域文本到 SQL 解析的主要挑战。 以前的工作要么需要人手干预来保证生成数据的质量,要么无法处理复杂的 SQL 查询。 本文提出了一个简单而有效的数据扩增框架。 首先, 根据一个数据库, 我们自动产生大量基于抽象语法树语法的 SQL 查询。 我们要求生成的查询至少涵盖培训数据中至少80%的 SQL 模式, 以便更好地匹配分布。 其次, 我们提出一个等级性 SQL 到问题生成模型, 以获得高质量的自然语言问题, 这是这项工作的主要贡献。 在三个跨域数据集上进行的实验, 即英语的WikisQL 和蜘蛛 以及中文的 DusQL, 表明我们提出的数据扩增框架可以不断提高强基线的性能, 特别是等级生成模型是改进的关键。