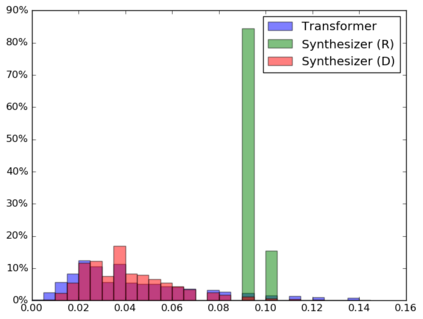
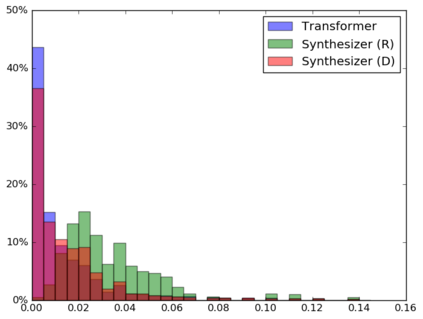
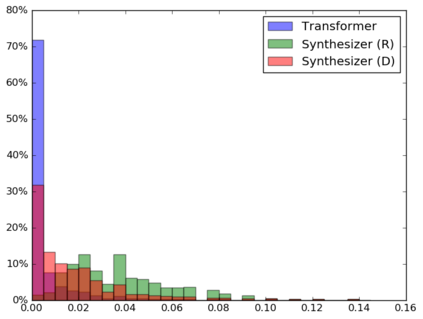
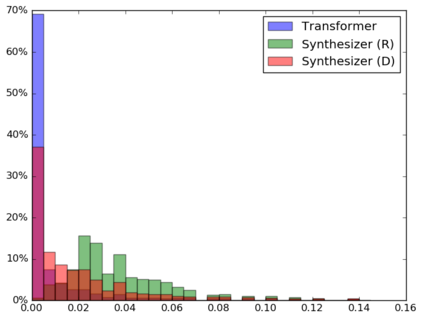
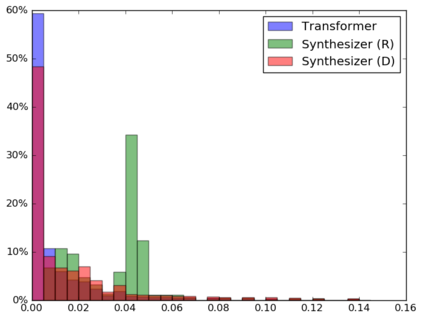
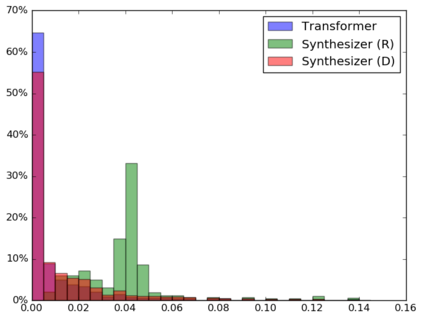
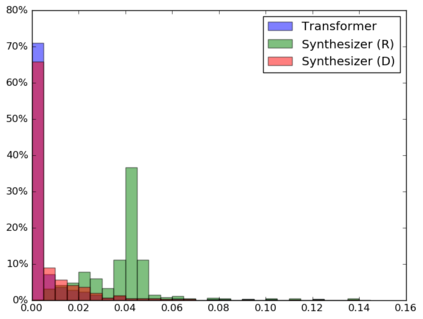
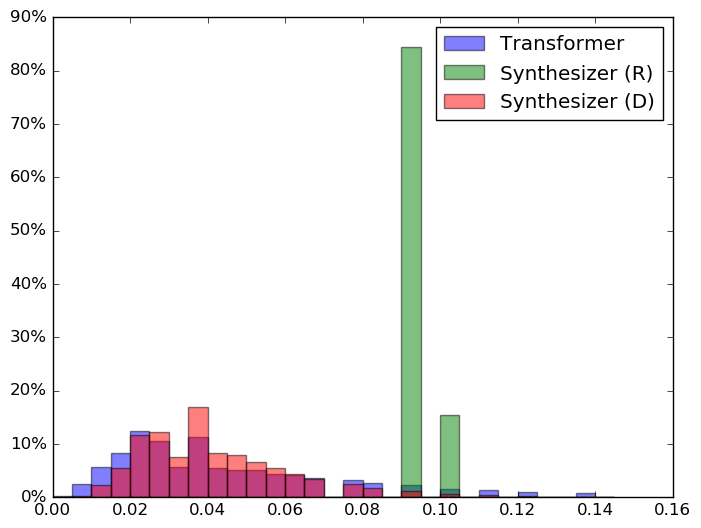
The dot product self-attention is known to be central and indispensable to state-of-the-art Transformer models. But is it really required? This paper investigates the true importance and contribution of the dot product-based self-attention mechanism on the performance of Transformer models. Via extensive experiments, we find that (1) random alignment matrices surprisingly perform quite competitively and (2) learning attention weights from token-token (query-key) interactions is useful but not that important after all. To this end, we propose \textsc{Synthesizer}, a model that learns synthetic attention weights without token-token interactions. In our experiments, we first show that simple Synthesizers achieve highly competitive performance when compared against vanilla Transformer models across a range of tasks, including machine translation, language modeling, text generation and GLUE/SuperGLUE benchmarks. When composed with dot product attention, we find that Synthesizers consistently outperform Transformers. Moreover, we conduct additional comparisons of Synthesizers against Dynamic Convolutions, showing that simple Random Synthesizer is not only $60\%$ faster but also improves perplexity by a relative $3.5\%$. Finally, we show that simple factorized Synthesizers can outperform Linformers on encoding only tasks.
翻译:点产品自我注意已知是最新变异器模型的核心和不可或缺的。 但是它是否真的需要? 本文调查了基于点产品的自我注意机制对于变异器模型性能的真正重要性和贡献。 通过广泛的实验, 我们发现(1) 随机校准矩阵具有相当的竞争力, 并且(2) 学习象征性( query- key) 互动( query- glue) 的注意权重是有用的, 但其实并不重要。 为此, 我们提议了\ textsc{ Synthesizer}, 这是一种在不进行象征性互动的情况下学习合成注意权重的模型。 在我们的实验中, 我们首先显示, 简单的合成器与香草变异器模型相比, 在一系列任务( 包括机器翻译、 语言建模、 文本生成和 GLUE/ SuperGLUE) 基准中, 取得了高度的竞争性能。 我们发现, 合成器与动态变异器相比, 我们还可以进行更多的比较, 显示简单的合成变异器( ) 能够以每美元更快速的方式显示一个更快速的合成变现。