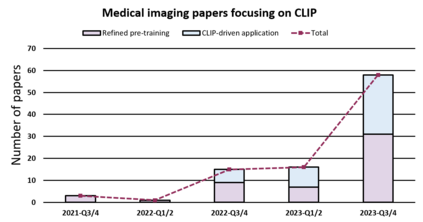
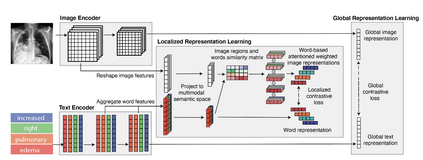
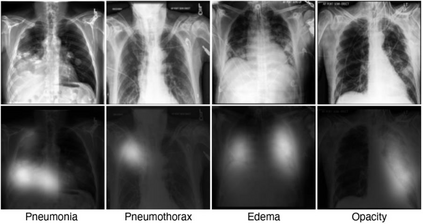
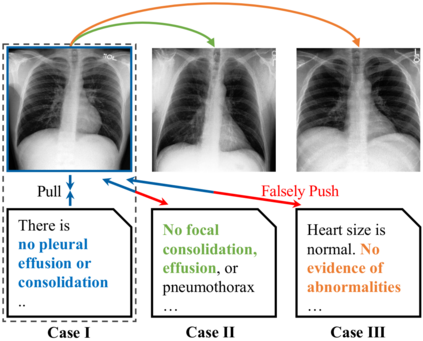
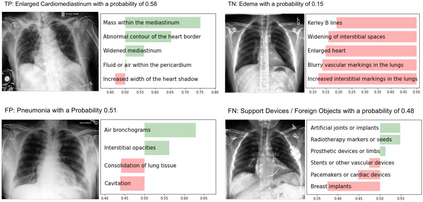
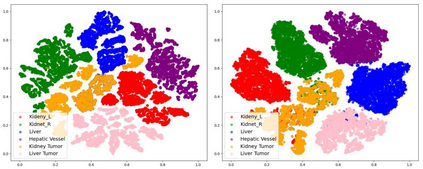
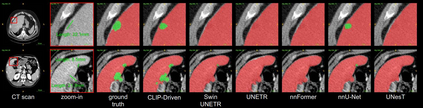
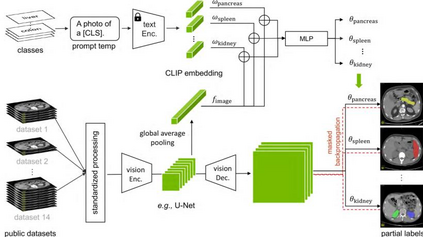
Contrastive Language-Image Pre-training (CLIP), a simple yet effective pre-training paradigm, successfully introduces text supervision to vision models. It has shown promising results across various tasks, attributable to its generalizability and interpretability. The use of CLIP has recently gained increasing interest in the medical imaging domain, serving both as a pre-training paradigm for aligning medical vision and language, and as a critical component in diverse clinical tasks. With the aim of facilitating a deeper understanding of this promising direction, this survey offers an in-depth exploration of the CLIP paradigm within the domain of medical imaging, regarding both refined CLIP pre-training and CLIP-driven applications. In this study, We (1) start with a brief introduction to the fundamentals of CLIP methodology. (2) Then, we investigate the adaptation of CLIP pre-training in the medical domain, focusing on how to optimize CLIP given characteristics of medical images and reports. (3) Furthermore, we explore the practical utilization of CLIP pre-trained models in various tasks, including classification, dense prediction, and cross-modal tasks. (4) Finally, we discuss existing limitations of CLIP in the context of medical imaging and propose forward-looking directions to address the demands of medical imaging domain. We expect that this comprehensive survey will provide researchers in the field of medical image analysis with a holistic understanding of the CLIP paradigm and its potential implications. The project page can be found on https://github.com/zhaozh10/Awesome-CLIP-in-Medical-Imaging.
翻译:暂无翻译