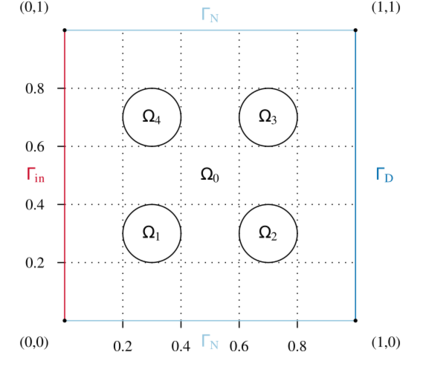
We present a subsampling strategy for the offline stage of the Reduced Basis Method. The approach is aimed at bringing down the considerable offline costs associated with using a finely-sampled training set. The proposed algorithm exploits the potential of the pivoted QR decomposition and the discrete empirical interpolation method to identify important parameter samples. It consists of two stages. In the first stage, we construct a low-fidelity approximation to the solution manifold over a fine training set. Then, for the available low-fidelity snapshots of the output variable, we apply the pivoted QR decomposition or the discrete empirical interpolation method to identify a set of sparse sampling locations in the parameter domain. These points reveal the structure of the parametric dependence of the output variable. The second stage proceeds with a subsampled training set containing a by far smaller number of parameters than the initial training set. Different subsampling strategies inspired from recent variants of the empirical interpolation method are also considered. Tests on benchmark examples justify the new approach and show its potential to substantially speed up the offline stage of the Reduced Basis Method, while generating reliable reduced-order models.
翻译:我们为 " 减少基础方法 " 的离线阶段提出了一个次抽样战略。该方法旨在降低与使用精细抽样培训集有关的大量离线费用。提议的算法利用了分解 QR 分解和独立的经验内插法的潜力来确定重要的参数样本。在第一阶段,我们用一套精细的培训集来构建一个低纤维近似值到多种解决方案。然后,对于产出变量现有的低纤维缩影,我们采用分解 QR 分解法或离散实验性内插法来确定参数域的一组稀有采样点。这些点揭示出产出变量的参数依赖性结构。第二阶段继续采用一组次抽样培训,其中包括比初步培训集少得多的参数。还考虑了从最近经验性内插法变种中得到的不同子抽样战略。关于基准示例的测试证明新的方法是合理的,并显示其潜力大大加快了基准模型的离线阶段,同时生成了可靠的模型。