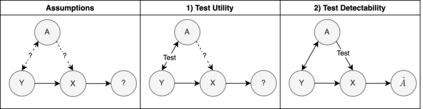
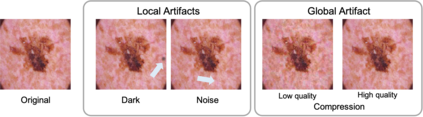
To safely deploy deep learning-based computer vision models for computer-aided detection and diagnosis, we must ensure that they are robust and reliable. Towards that goal, algorithmic auditing has received substantial attention. To guide their audit procedures, existing methods rely on heuristic approaches or high-level objectives (e.g., non-discrimination in regards to protected attributes, such as sex, gender, or race). However, algorithms may show bias with respect to various attributes beyond the more obvious ones, and integrity issues related to these more subtle attributes can have serious consequences. To enable the generation of actionable, data-driven hypotheses which identify specific dataset attributes likely to induce model bias, we contribute a first technique for the rigorous, quantitative screening of medical image datasets. Drawing from literature in the causal inference and information theory domains, our procedure decomposes the risks associated with dataset attributes in terms of their detectability and utility (defined as the amount of information knowing the attribute gives about a task label). To demonstrate the effectiveness and sensitivity of our method, we develop a variety of datasets with synthetically inserted artifacts with different degrees of association to the target label that allow evaluation of inherited model biases via comparison of performance against true counterfactual examples. Using these datasets and results from hundreds of trained models, we show our screening method reliably identifies nearly imperceptible bias-inducing artifacts. Lastly, we apply our method to the natural attributes of a popular skin-lesion dataset and demonstrate its success. Our approach provides a means to perform more systematic algorithmic audits and guide future data collection efforts in pursuit of safer and more reliable models.
翻译:为了安全地部署基于深度学习的计算机视觉模型用于辅助检测和诊断,我们必须确保它们具有强大的鲁棒性和可靠性。为此目的,算法审计已经引起了广泛关注。为了指导审计程序,现有方法依赖于启发式方法或高级目标(例如,针对受保护属性的非歧视性,如性别、性别或种族)。然而,与各种属性相关的算法可能显示出偏见,而与这些更微妙的属性相关的完整性问题可能会产生严重后果。为了生成行动可行的,数据驱动的假设,识别特定的数据集属性,可能会引起模型偏差,我们为医学图像数据集的严格,定量筛查提供了一种首次技术。从因果推论和信息理论领域的文献中汲取,我们的程序根据数据集属性的可检测性和效用(定义为知道属性关于任务标签给出的信息量)来分解与数据集属性相关的风险。为证明我们方法的有效性和灵敏性,我们开发了各种数据集,通过不同程度与目标标签相关的合成插入伪影,以通过与真实反事实的比较评估继承模型偏见。使用这些数据集和数百个受训模型的结果,我们证明了我们的筛查方法可靠地识别几乎不可察觉的偏见诱导物。最后,我们将我们的方法应用到流行的皮肤病变数据集的自然属性上,并展示其成功。我们的方法提供了一种执行更系统的算法审计和指导未来数据收集工作的途径,以追求更安全和可靠的模型。