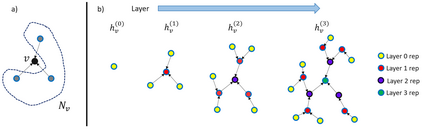
Image analysis and machine learning algorithms operating on multi-gigapixel whole-slide images (WSIs) often process a large number of tiles (sub-images) and require aggregating predictions from the tiles in order to predict WSI-level labels. In this paper, we present a review of existing literature on various types of aggregation methods with a view to help guide future research in the area of computational pathology (CPath). We propose a general CPath workflow with three pathways that consider multiple levels and types of data and the nature of computation to analyse WSIs for predictive modelling. We categorize aggregation methods according to the context and representation of the data, features of computational modules and CPath use cases. We compare and contrast different methods based on the principle of multiple instance learning, perhaps the most commonly used aggregation method, covering a wide range of CPath literature. To provide a fair comparison, we consider a specific WSI-level prediction task and compare various aggregation methods for that task. Finally, we conclude with a list of objectives and desirable attributes of aggregation methods in general, pros and cons of the various approaches, some recommendations and possible future directions.
翻译:在多igapixel 整流图像上运行的图像分析和机器学习算法经常处理大量瓷砖(次图像),需要从瓷砖中进行综合预测,以预测西硅酸等级的标签。在本文件中,我们介绍了关于各种类型的聚合方法的现有文献,以帮助指导今后在计算病理学(CPath)领域的研究。我们提议了一个通用的CPath工作流程,其中有三个路径,考虑到数据的不同层次和类型以及分析西硅酸盐的计算性质,以便预测建模。我们根据数据的背景和表示、计算模块的特点和CPath使用案例对汇总方法进行了分类。我们比较和比较了基于多实例学习原则的不同方法,或许是最常用的汇总方法,涵盖多种CPath文献。为了进行公平的比较,我们考虑一个特定的WSI级别预测任务,并比较用于这项工作的各种汇总方法。最后,我们根据一般的聚合方法、各种方法的准点和准点、一些可能的建议以及未来方向的目标和适当属性列表。