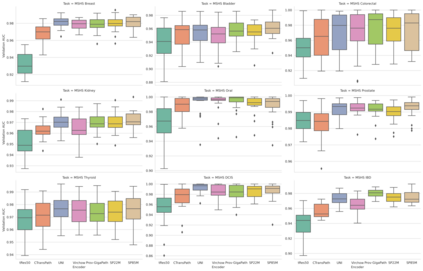
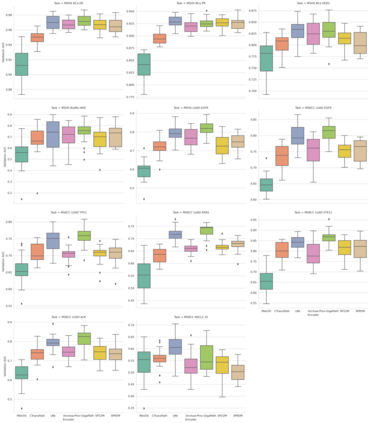
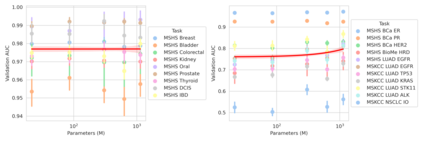
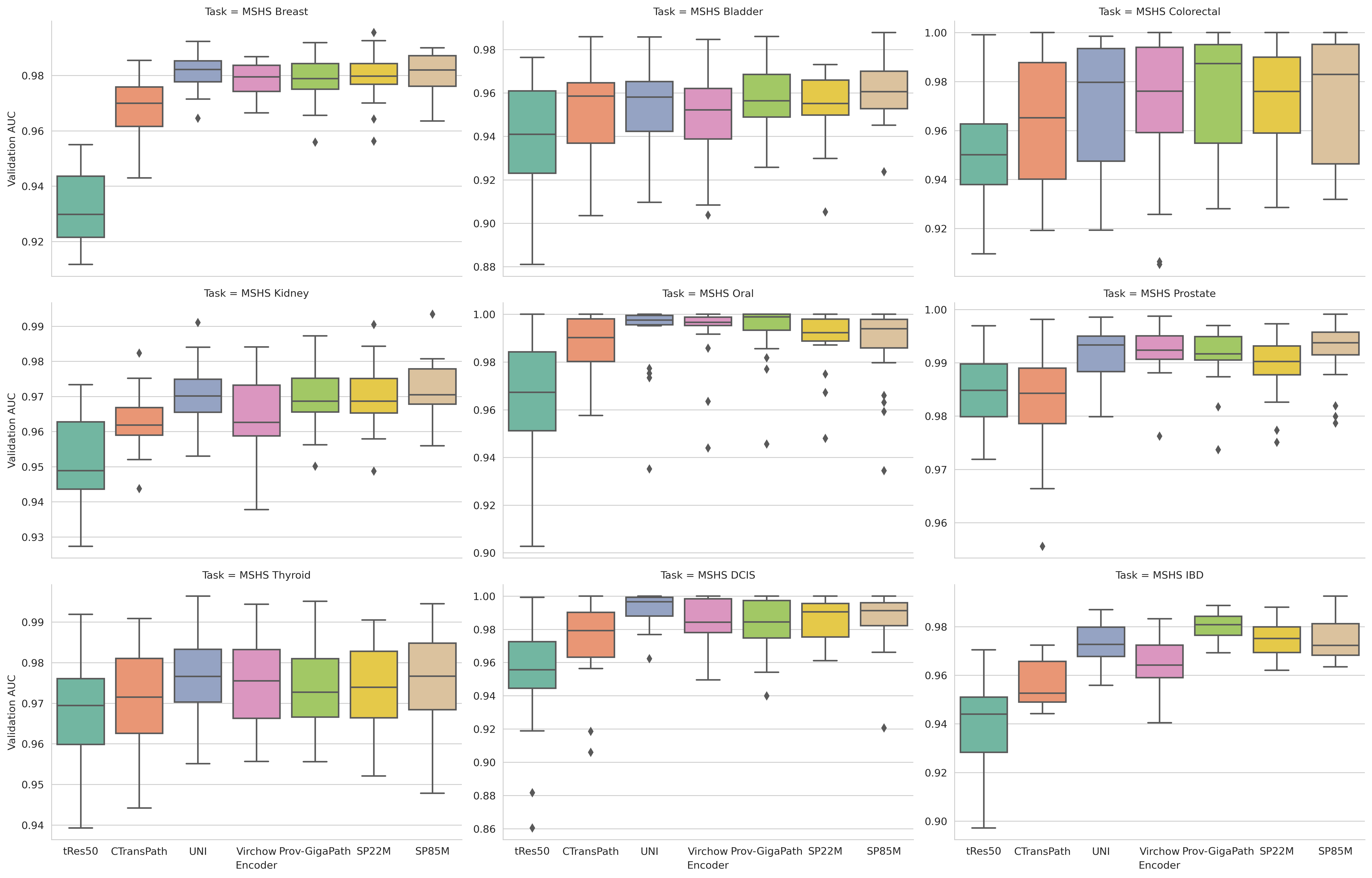
The use of self-supervised learning (SSL) to train pathology foundation models has increased substantially in the past few years. Notably, several models trained on large quantities of clinical data have been made publicly available in recent months. This will significantly enhance scientific research in computational pathology and help bridge the gap between research and clinical deployment. With the increase in availability of public foundation models of different sizes, trained using different algorithms on different datasets, it becomes important to establish a benchmark to compare the performance of such models on a variety of clinically relevant tasks spanning multiple organs and diseases. In this work, we present a collection of pathology datasets comprising clinical slides associated with clinically relevant endpoints including cancer diagnoses and a variety of biomarkers generated during standard hospital operation from two medical centers. We leverage these datasets to systematically assess the performance of public pathology foundation models and provide insights into best practices for training new foundation models and selecting appropriate pretrained models.
翻译:暂无翻译