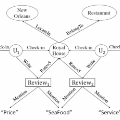
Heterogeneous information network (HIN) embedding aims to find the representations of nodes that preserve the proximity between entities of different nature. A family of approaches that are wildly adopted applies random walk to generate a sequence of heterogeneous context, from which the embedding is learned. However, due to the multipartite graph structure of HIN, hub nodes tend to be over-represented in the sampled sequence, giving rise to imbalanced samples of the network. Here we propose a new embedding method CoarSAS2hvec. The self-avoid short sequence sampling with the HIN coarsening procedure (CoarSAS) is utilized to better collect the rich information in HIN. An optimized loss function is used to improve the performance of the HIN structure embedding. CoarSAS2hvec outperforms nine other methods in two different tasks on four real-world data sets. The ablation study confirms that the samples collected by CoarSAS contain richer information of the network compared with those by other methods, which is characterized by a higher information entropy. Hence, the traditional loss function applied to samples by CoarSAS can also yield improved results. Our work addresses a limitation of the random-walk-based HIN embedding that has not been emphasized before, which can shed light on a range of problems in HIN analyses.
翻译:混合信息网络(HIN)嵌入的目的是找到保存不同性质实体之间近距离的节点的表示方式。 野生采用的一系列方法运用随机行走来生成一系列不同环境的序列, 从而学习嵌入。 但是,由于HIN的多部分图形结构, 中心节点在抽样序列中往往代表过多, 从而导致网络的样本出现不平衡。 我们在这里建议采用一个新的嵌入方法 CoarSASAS2hvec。 使用HIN 共分析程序( CoarSASAS) 自行避免短顺序取样来更好地收集 HIN 中的丰富信息。 优化损失功能被用来改进 HIN 嵌入结构的性能。 CoarSAS2hvec 在四个真实世界数据集的两个不同任务中超越了其他九种方法。 校正研究证实, CoarSAS 收集的网络样本与其他方法相比含有更丰富的信息, 而其他方法的特征是更高的信息封存地址。 因此, CONASA 用于样本的传统损失功能在CONSAS 进行随机测算之前也能够改进结果。