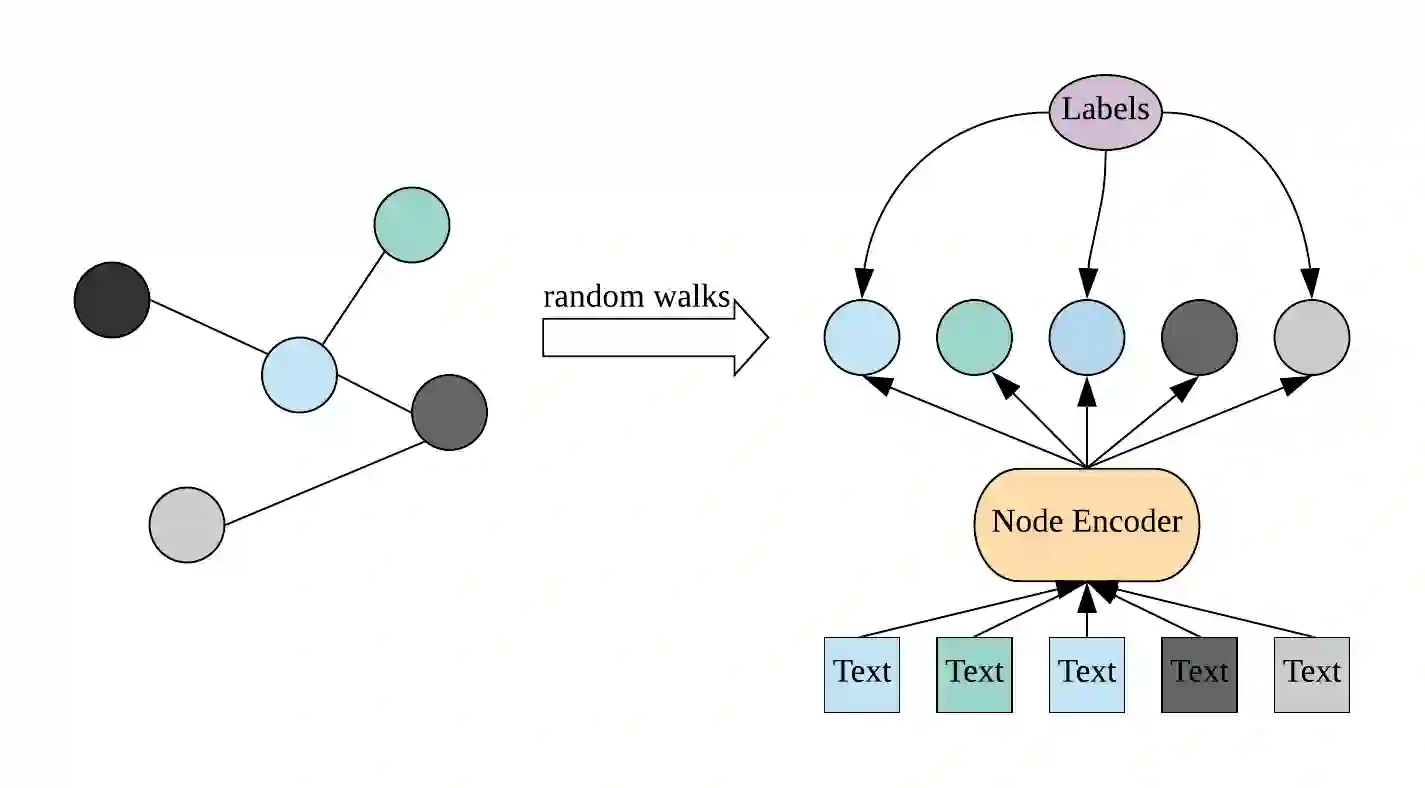
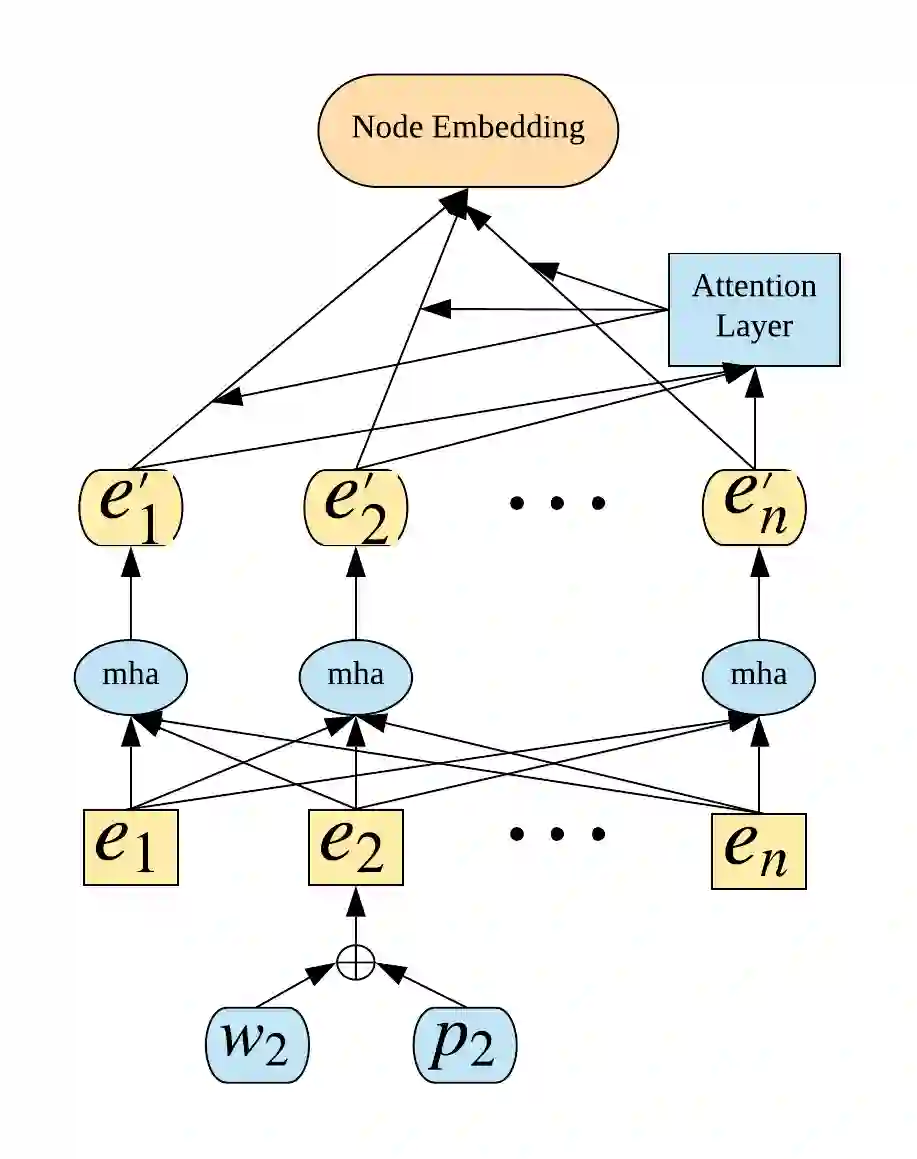
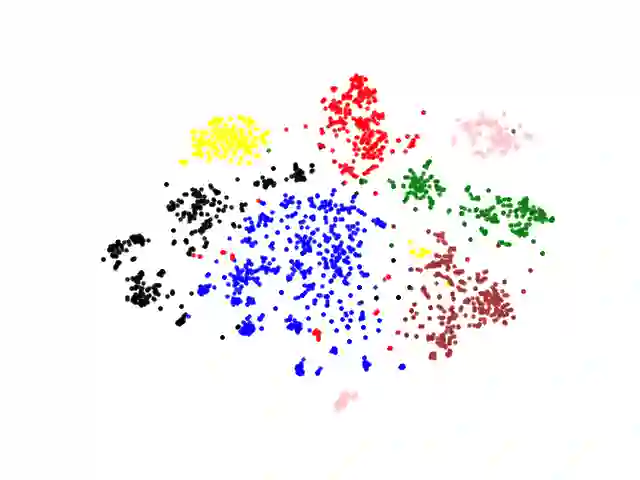
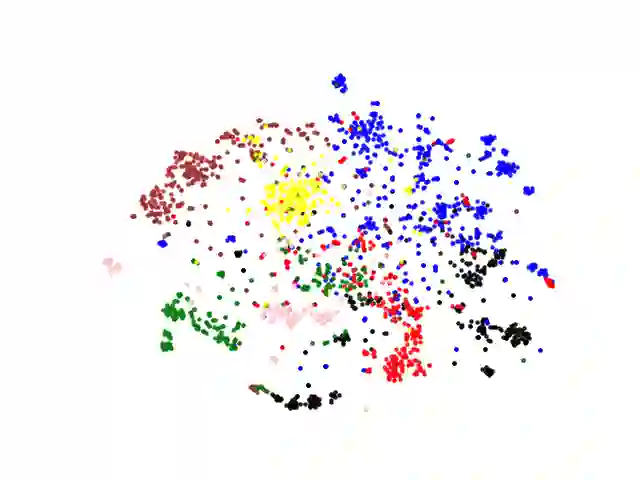
Voluminous works have been implemented to exploit content-enhanced network embedding models, with little focus on the labelled information of nodes. Although TriDNR leverages node labels by treating them as node attributes, it fails to enrich unlabelled node vectors with the labelled information, which leads to the weaker classification result on the test set in comparison to existing unsupervised textual network embedding models. In this study, we design an integrated node encoder (INE) for textual networks which is jointly trained on the structure-based and label-based objectives. As a result, the node encoder preserves the integrated knowledge of not only the network text and structure, but also the labelled information. Furthermore, INE allows the creation of label-enhanced vectors for unlabelled nodes by entering their node contents. Our node embedding achieves state-of-the-art performances in the classification task on two public citation networks, namely Cora and DBLP, pushing benchmarks up by 10.0\% and 12.1\%, respectively, with the 70\% training ratio. Additionally, a feasible solution that generalizes our model from textual networks to a broader range of networks is proposed.
翻译:为开发内容强化网络嵌入模型,已开展了光学工程,以开发内容强化网络嵌入模型,很少注重节点的标签。尽管TRIDNR通过将节点标签视为节点属性来利用节点标签,但它未能用标签信息来丰富无标签节点矢量,这导致测试集与现有的未经监管的文本网络嵌入模型相比,分类结果较弱。在这项研究中,我们为文本网络设计了一个综合节点编码器(INE),该节点对基于结构和标签的目标进行了联合培训。因此,节点编码器不仅保存了网络文本和结构的综合知识,而且还保存了标签信息。此外,INE允许通过输入节点内容,为未标签节点创建标签强化矢量。我们的节点嵌在两个公共引用网络,即科拉和DBLP的分类任务中达到了最先进的性能,将基准分别推升至10.0和12.1%,同时保留了网络文本和70 ⁇ 培训比率。此外,一个可行的解决方案是从更广泛的文本网络范围。