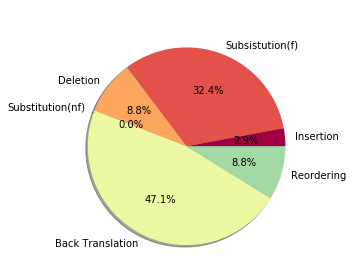
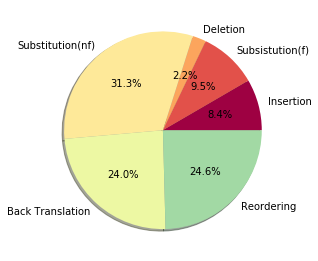
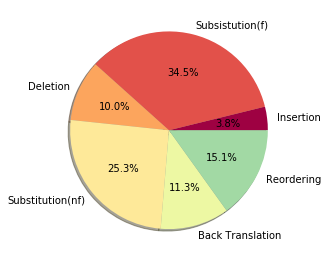
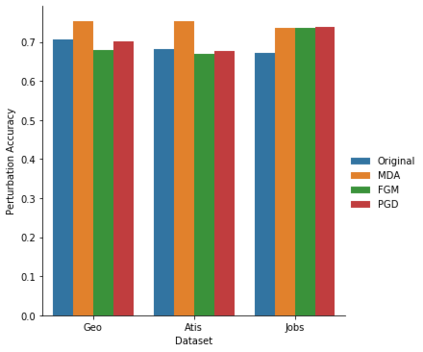
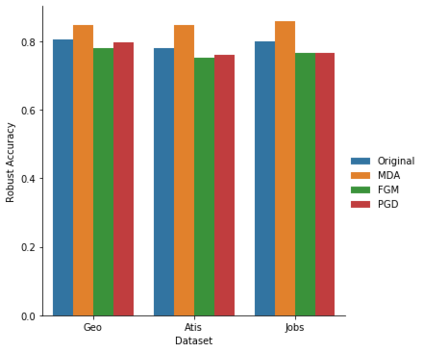
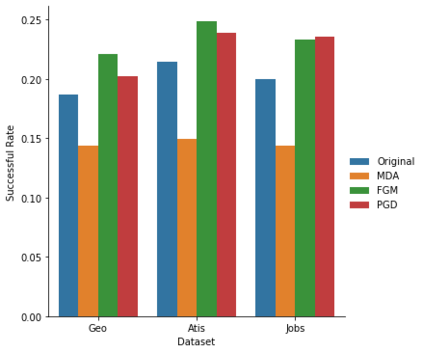
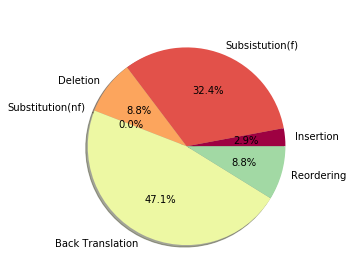
Semantic parsing maps natural language (NL) utterances into logical forms (LFs), which underpins many advanced NLP problems. Semantic parsers gain performance boosts with deep neural networks, but inherit vulnerabilities against adversarial examples. In this paper, we provide the empirical study on the robustness of semantic parsers in the presence of adversarial attacks. Formally, adversaries of semantic parsing are considered to be the perturbed utterance-LF pairs, whose utterances have exactly the same meanings as the original ones. A scalable methodology is proposed to construct robustness test sets based on existing benchmark corpora. Our results answered five research questions in measuring the sate-of-the-art parsers' performance on robustness test sets, and evaluating the effect of data augmentation.
翻译:语义分析将自然语言(NL)的表达方式映射成逻辑形式(LFs),这是许多先进的NLP问题的基础。语义分析员通过深厚的神经网络获得性能提升,但继承了对抗性实例的弱点。在本文中,我们提供了关于语义分析员在对抗性攻击面前的稳健性的经验研究。形式上,语义分析对手被视为有扰动的言语-LF的对子,其语义与最初的对子有着完全相同的含义。提出了一种可测量的方法,以根据现有的基准子体构建稳健性测试组。我们的结果回答了五个研究问题,即测量数位数位分析员在稳健性测试组上的性能,评估数据增强的效果。