【导读】作为世界数据挖掘领域的最高级别的学术会议,ACM SIGKDD(国际数据挖掘与知识发现大会,简称 KDD)每年都会吸引全球领域众多专业人士参与。今年的 KDD大会计划将于 2020 年 8 月 23 日 ~27 日在美国美国加利福尼亚州圣地亚哥举行(疫情影响,线上举行)。KDD 2020官方发布接收论文,共有1279篇论文提交到Research Track,共216篇被接收,接收率16.8%。近期一些Paper放出来了,为此,专知小编提前为大家整理了五篇KDD 2020 推荐系统(RS)相关论文,供大家参考。——异构图交互模型、组合嵌入、分解自监督、地理感知序列推荐、交互路径推理。
KDD2020 Accepted Papers
CVPR2020SGNN、CVPR2020GNN_Part2、CVPR2020GNN_Part1、WWW2020GNN_Part1、AAAI2020GNN、ACMMM2019GNN、CIKM2019GNN、ICLR2020GNN、EMNLP2019GNN、ICCV2019GNN_Part2、ICCV2019GNN_Part1、NIPS2019GNN、IJCAI2019GNN_Part1、IJCAI2019GNN_Part2、KDD2019GNN、ACL2019GNN、CVPR2019GNN、
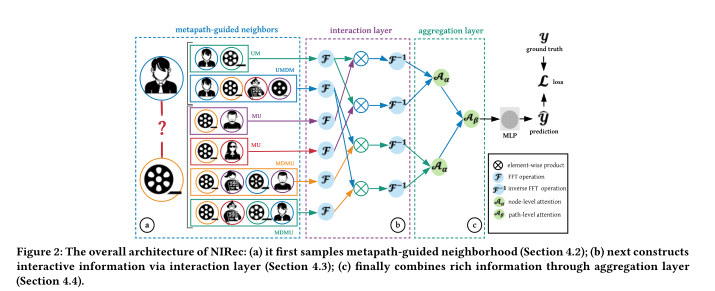
1、An Efficient Neighborhood-based Interaction Model for Recommendation on Heterogeneous Graph
作者:Jiarui Jin, Jiarui Qin, Yuchen Fang, Kounianhua Du, Weinan Zhang, Yong Yu, Zheng Zhang, Alexander J. Smola
摘要:近年来,基于异构信息网络(HIN)的推荐系统大量涌现,因为HIN能够刻画复杂的图形,并且包含丰富的语义。现有的方法虽然取得了性能上的提高,但同时在实用性方面,仍然面临着以下问题。一方面,大多数现有的基于HIN的方法依赖于显式路径可达性来利用用户和项目之间基于路径的语义相关性,例如基于元路径的相似性。但由于路径连接稀疏或有噪声,这些方法很难使用和集成,并且通常具有不同的长度。另一方面,其他基于图的方法旨在通过在预测前将节点及其邻域信息压缩成单个嵌入来学习有效的异构网络表示。这种弱耦合的建模方式忽略了节点之间丰富的交互,这带来了先前概述的问题。针对上述问题,本文提出了一种端到端基于邻域的交互推荐模型(NIRec)。具体地说,我们首先分析了学习交互在HINS中的重要性,然后提出了一种新的公式,通过元路径引导的邻域来捕捉每对节点之间的交互模式。然后,为了探索元路径之间的复杂交互和处理大规模网络上的学习复杂性,我们用卷积的方式表示交互,并使用快速傅立叶变换进行高效的学习。在四种不同类型的异构图上的大量实验表明,与现有技术相比,NIRec的性能有所提高。据我们所知,这是在基于HIN的推荐中提供有效的基于邻域的交互模型的第一项工作。
网址: https://arxiv.org/abs/2007.00216
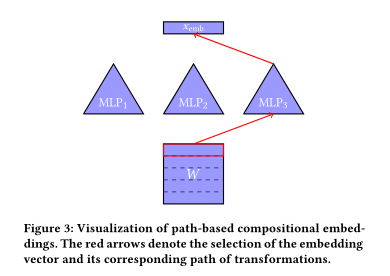
2、Compositional Embeddings Using Complementary Partitions for Memory-Efficient Recommendation Systems
作者:Hao-Jun Michael Shi, Dheevatsa Mudigere, Maxim Naumov, Jiyan Yang
摘要:基于深度学习的推荐系统利用了成百上千个不同的分类特征,每个分类特征都有数百万个从点击到发布的不同类别。为了尊重分类数据中的自然多样性,嵌入将每个类别映射到嵌入空间内的统一表示。由于每个分类特征可以承担多达数千万个不同的可能类别,因此嵌入表示在训练和推理过程中都面临着存储瓶颈。我们提出了一种新的方法,通过利用类别集合的互补划分(complementary partitions)在不需要明确定义的情况下来为每个类别产生唯一的嵌入向量,从而以端到端的方式减少嵌入大小。通过在每个互补分区上存储多个较小的嵌入表,并结合每个表的嵌入,我们以较小的存储开销为每个类别定义了唯一的嵌入。该方法可以被解释为使用特定的固定码本(fixed codebook)来确保每个类别表示的唯一性。我们的实验结果表明,相对于散列技巧,我们的方法在减少模型损失和准确性的同时减小了参数数量,并且有效地减少了嵌入表示的大小。
网址: https://arxiv.org/abs/1909.02107
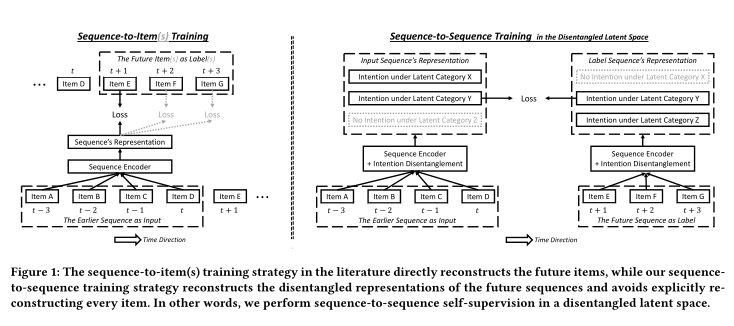
3、Disentangled Self-Supervision in Sequential Recommenders
作者:Jianxin Ma, Chang Zhou, Hongxia Yang, Peng Cui, Xin Wang, Wenwu Zhu
摘要:为了学习一个序列推荐器,现有的方法通常采用sequence-to-item(Seq2item)训练策略,该策略以用户的下一次行为为标签,以用户过去的行为为输入来监督序列模型。然而,seq2item策略是目光短浅的,通常会产生单一的推荐列表。在本文中,我们着眼于更长远的未来来研究挖掘额外信号以进行监督的问题。存在如下两个挑战:i)重构包含多个行为的未来序列比重构单个下一个行为要困难得多,这可能导致收敛困难;ii)所有未来行为的序列可能涉及多个意图,并不是所有的意图都可以从先前行为序列中预测出来。为了应对这些挑战,我们提出了一种基于潜在自监督和解缠(disentanglement)的Seq2seq训练策略。具体地说,我们在潜在空间中进行自监督,即作为一个整体重构未来序列的表示,而不是单独重构未来序列中的项。我们还解开了任何给定行为序列背后的意图,并仅使用涉及共同意图的子序列对来构建seq2seq训练样本。真实世界基准和合成数据的结果表明,seq2seq训练带来了改进。
网址: http://pengcui.thumedialab.com/papers/DisentangledSequentialRecommendation.pdf
4、Geography-Aware Sequential Location Recommendation
作者:Defu Lian, Yongji Wu, Yong Ge, Xing Xie, Enhong Chen
摘要:序列位置推荐在移动性预测、路径规划、基于位置广告等应用中发挥着重要作用。虽然从张量分解发展到基于RNN的神经网络,但现有方法没有有效利用地理信息,存在稀疏性问题。为此,我们提出了一种基于自注意力网络的地理感知序列推荐器(GeoSAN)进行位置推荐。一方面,我们提出了一种新的基于重要性抽样的损失函数进行优化,通过强调使用信息丰富的负样本来解决稀疏性问题。另一方面,为了更好地利用地理信息,GeoSAN使用基于自注意力的地理编码器来表示每个GPS点的分层网格。此外,我们还提出了地理感知的负采样器来提高负样本的信息量。我们使用三个真实的LBSN数据集对所提出的算法进行了评估,结果表明GeoSAN的性能比最新的序列位置推荐器高出34.9%。实验结果进一步验证了新的损失函数、地理编码器和地理感知负采样器的有效性。
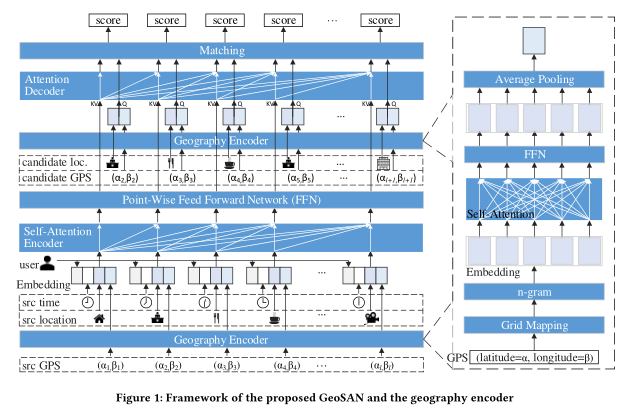
网址: http://staff.ustc.edu.cn/~liandefu/paper/locpred.pdf
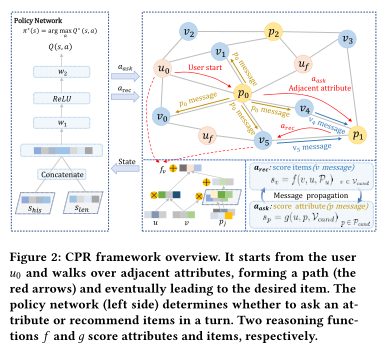
5、Interactive Path Reasoning on Graph for Conversational Recommendation
作者:Wenqiang Lei, Gangyi Zhang, Xiangnan He, Yisong Miao, Xiang Wang, Liang Chen, Tat-Seng Chua
摘要:传统的推荐系统从过去的交互历史中估计用户对项目的偏好,因此受到获取细粒度和动态用户偏好的限制。会话推荐系统(CRS)使系统能够直接向用户询问他们对物品的偏好属性,从而为这些限制带来了革命性的变化。然而,现有的CRS方法并没有充分利用这一优势-它们只以相当隐含的方式使用属性反馈,例如更新潜在用户表示。在本文中,我们提出了转换路径推理(Conversational Path Reasoning, CPR),这是一个通用的框架,它将会话推荐建模为图上的交互式路径推理问题。它通过跟随用户反馈遍历属性顶点,显式地利用用户偏好属性。通过利用图结构,CPR能够删除许多不相关的候选属性,从而获得更好的命中用户偏好属性的机会。为了演示CPR的工作原理,我们提出了一个简单而有效的实例化,命名为SCPR(SimpleCPR)。我们对多轮会话推荐场景进行了实证研究,这是迄今为止最现实的CRS场景,它考虑了多轮询问属性和推荐项目。通过在Yelp和LastFM两个数据集上的大量实验,我们验证了我们的SCPR的有效性,它的性能明显优于最先进的CRS方法EAR和CRM。特别地,属性越多,我们的方法就能获得越多的优势。