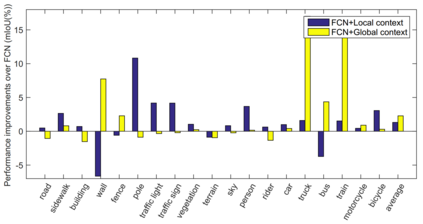
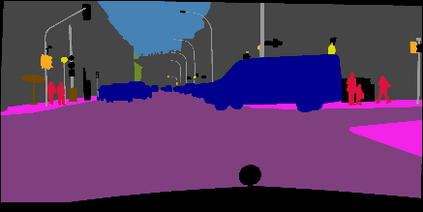
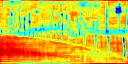
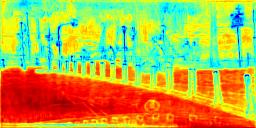
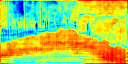
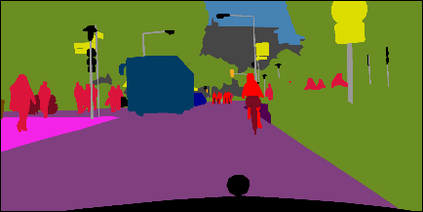
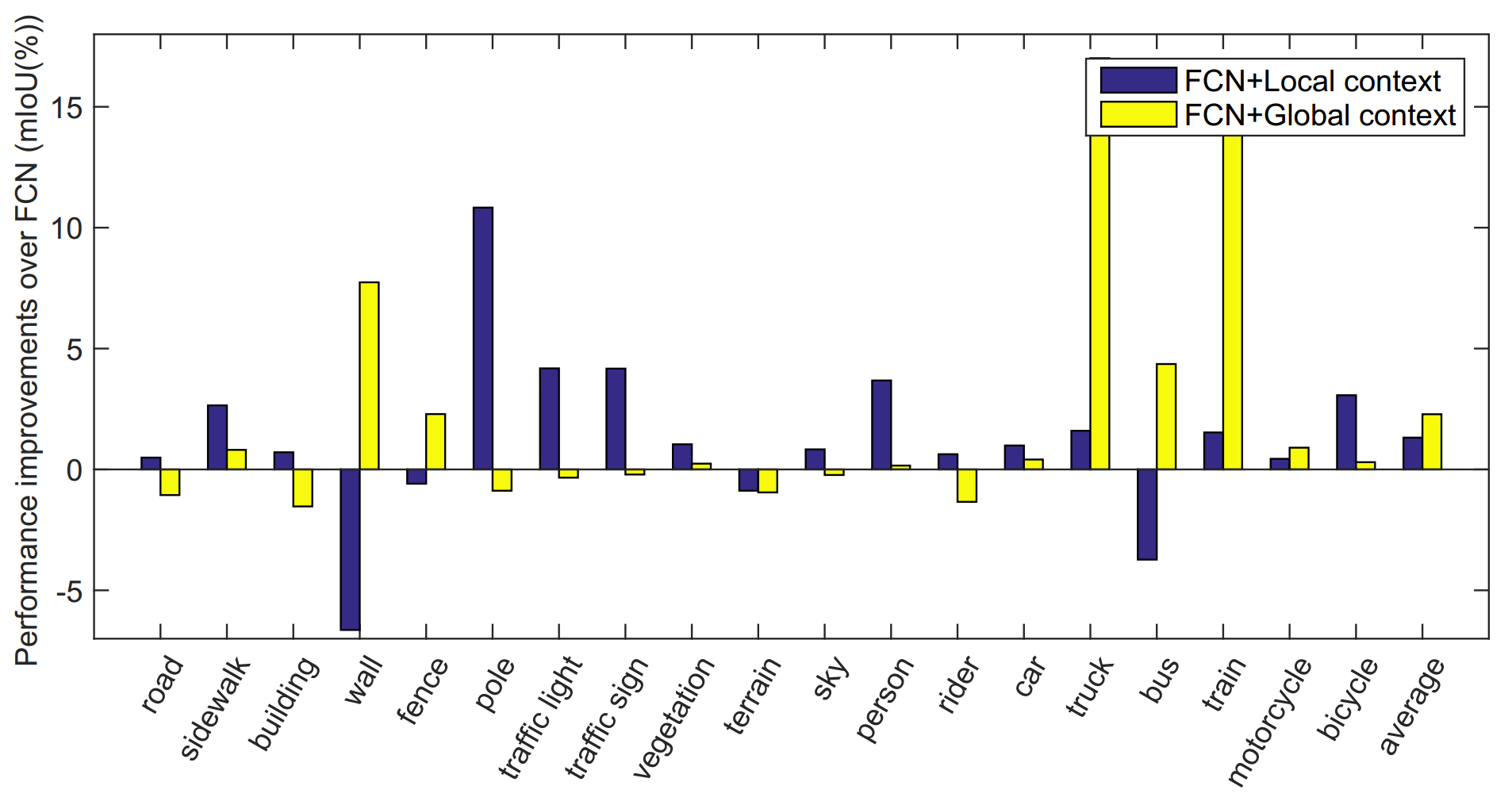
Recent works attempt to improve scene parsing performance by exploring different levels of contexts, and typically train a well-designed convolutional network to exploit useful contexts across all pixels equally. However, in this paper, we find that the context demands are varying from different pixels or regions in each image. Based on this observation, we propose an Adaptive Context Network (ACNet) to capture the pixel-aware contexts by a competitive fusion of global context and local context according to different per-pixel demands. Specifically, when given a pixel, the global context demand is measured by the similarity between the global feature and its local feature, whose reverse value can be used to measure the local context demand. We model the two demand measurements by the proposed global context module and local context module, respectively, to generate adaptive contextual features. Furthermore, we import multiple such modules to build several adaptive context blocks in different levels of network to obtain a coarse-to-fine result. Finally, comprehensive experimental evaluations demonstrate the effectiveness of the proposed ACNet, and new state-of-the-arts performances are achieved on all four public datasets, i.e. Cityscapes, ADE20K, PASCAL Context, and COCO Stuff.
翻译:最近的工作试图通过探索不同程度的环境来改善场景分辨,并典型地培训一个设计周密的革命网络,以平等地利用所有像素的有用环境。然而,在本文件中,我们发现背景需求与每个图像的不同像素或区域不同。根据这一观察,我们建议建立一个适应性环境网络(ACNet),通过竞争性地结合全球背景和地方背景,根据不同的人均需求来捕捉像素。具体地说,如果给一个像素,全球背景需求是通过全球特征与地方特征之间的相似性来衡量的,而全球特征与地方特征的相似性,其反向价值可以用来测量当地背景需求。我们用拟议的全球背景模块和当地背景模块分别模拟两种需求测量,以产生适应性环境特征。此外,我们输入多个这样的模块,以在不同级别的网络中建立若干适应性环境区块,以获得粗略的至细微的结果。最后,全面的实验性评估表明,拟议的ACNet和新的状态表现在所有四个公共数据背景下都取得了效果,例如,Stax20 和CO-CAR。