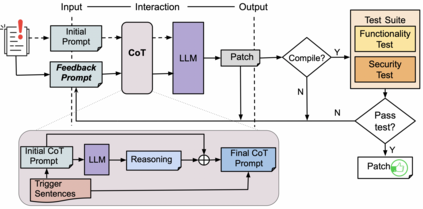
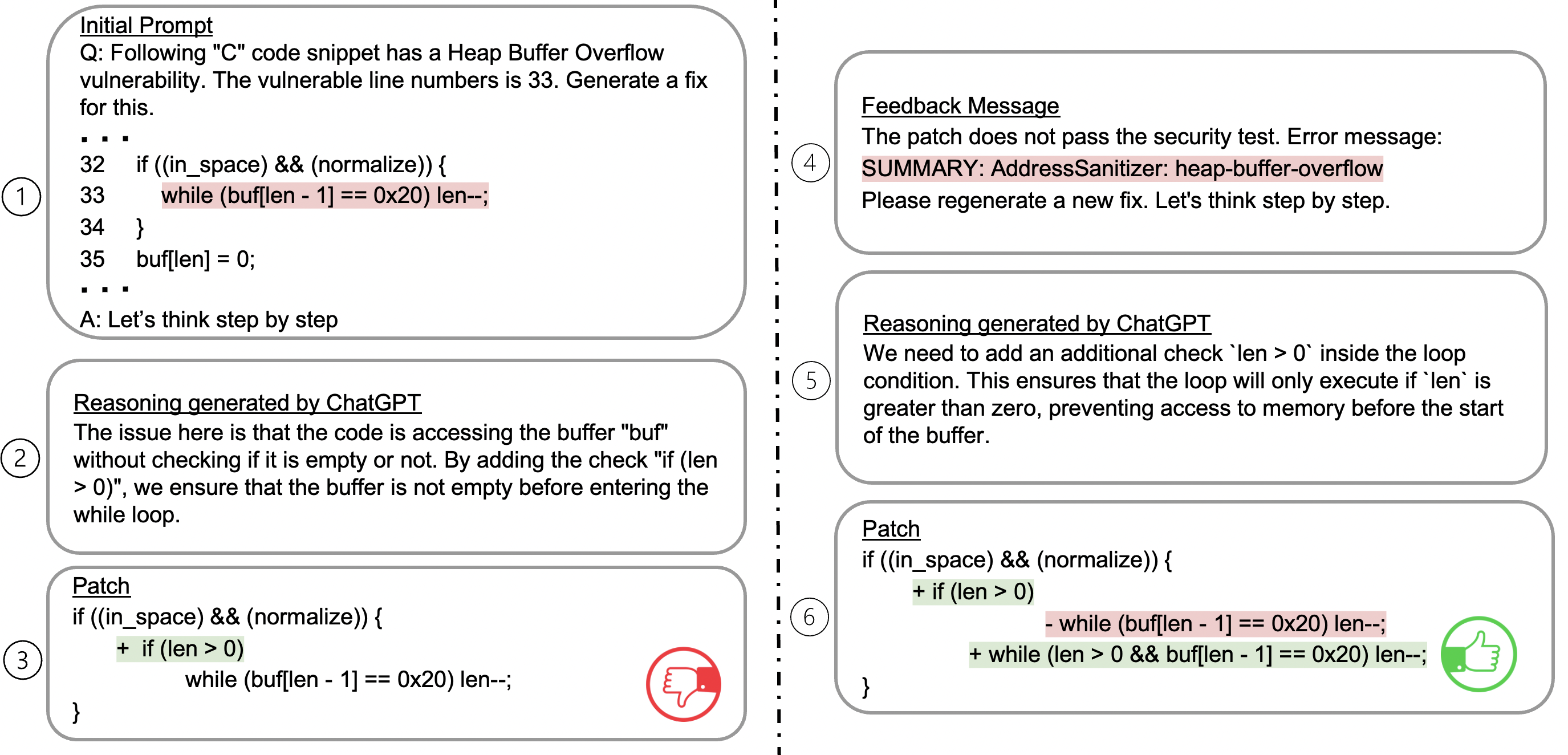
Recent work in automated program repair (APR) proposes the use of reasoning and patch validation feedback to reduce the semantic gap between the LLMs and the code under analysis. The idea has been shown to perform well for general APR, but its effectiveness in other particular contexts remains underexplored. In this work, we assess the impact of reasoning and patch validation feedback to LLMs in the context of vulnerability repair, an important and challenging task in security. To support the evaluation, we present VRpilot, an LLM-based vulnerability repair technique based on reasoning and patch validation feedback. VRpilot (1) uses a chain-of-thought prompt to reason about a vulnerability prior to generating patch candidates and (2) iteratively refines prompts according to the output of external tools (e.g., compiler, code sanitizers, test suite, etc.) on previously-generated patches. To evaluate performance, we compare VRpilot against the state-of-the-art vulnerability repair techniques for C and Java using public datasets from the literature. Our results show that VRpilot generates, on average, 14% and 7.6% more correct patches than the baseline techniques on C and Java, respectively. We show, through an ablation study, that reasoning and patch validation feedback are critical. We report several lessons from this study and potential directions for advancing LLM-empowered vulnerability repair
翻译:暂无翻译