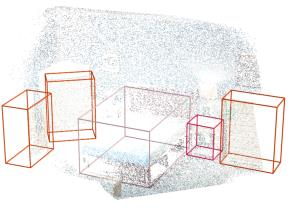
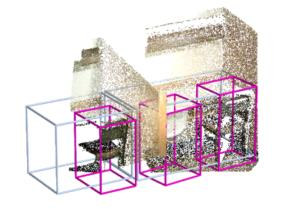
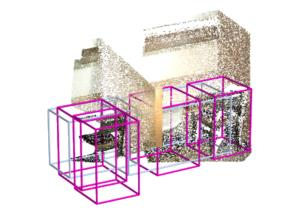
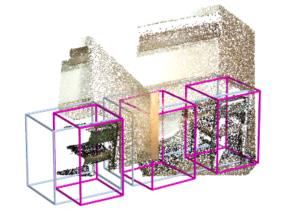
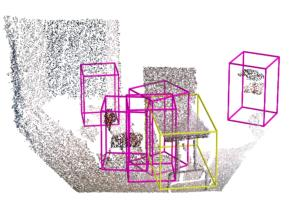
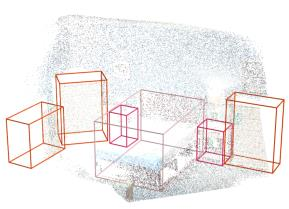
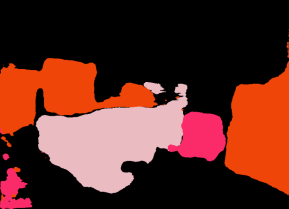
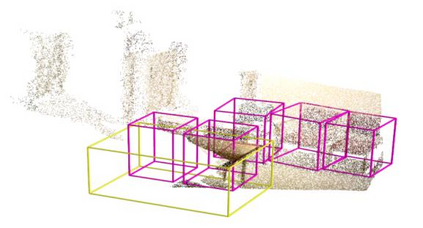
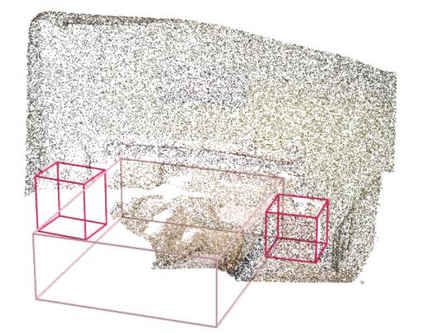
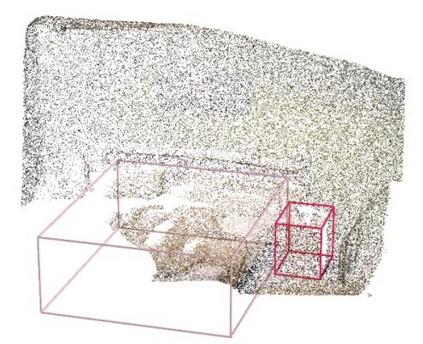
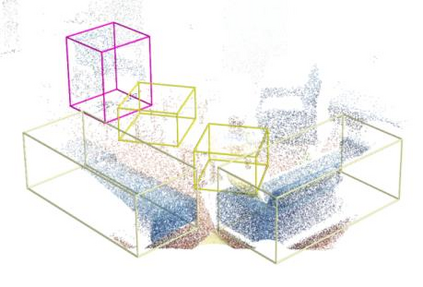
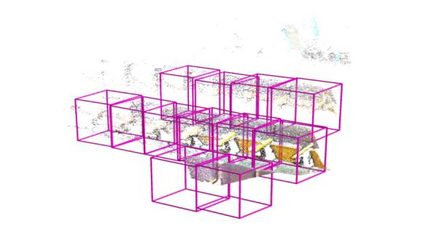
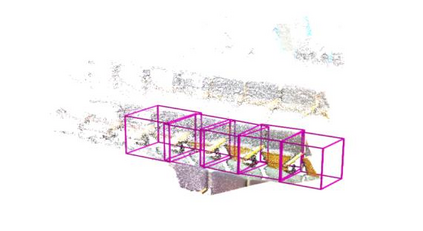
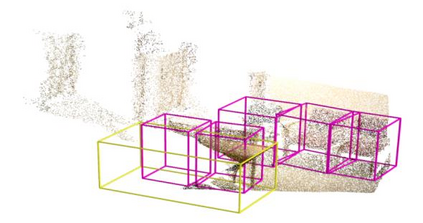
Point clouds and RGB images are naturally complementary modalities for 3D visual understanding - the former provides sparse but accurate locations of points on objects, while the latter contains dense color and texture information. Despite this potential for close sensor fusion, many methods train two models in isolation and use simple feature concatenation to represent 3D sensor data. This separated training scheme results in potentially sub-optimal performance and prevents 3D tasks from being used to benefit 2D tasks that are often useful on their own. To provide a more integrated approach, we propose a novel Multi-Modality Task Cascade network (MTC-RCNN) that leverages 3D box proposals to improve 2D segmentation predictions, which are then used to further refine the 3D boxes. We show that including a 2D network between two stages of 3D modules significantly improves both 2D and 3D task performance. Moreover, to prevent the 3D module from over-relying on the overfitted 2D predictions, we propose a dual-head 2D segmentation training and inference scheme, allowing the 2nd 3D module to learn to interpret imperfect 2D segmentation predictions. Evaluating our model on the challenging SUN RGB-D dataset, we improve upon state-of-the-art results of both single modality and fusion networks by a large margin ($\textbf{+3.8}$ mAP@0.5). Code will be released $\href{https://github.com/Divadi/MTC_RCNN}{\text{here.}}$
翻译:云层和 RGB 图像自然是3D 视觉理解的互补模式----前者为对象提供了稀少但准确的点点位置,而后者则含有浓密的颜色和纹理信息。尽管存在这种近距离感官融合的潜力,但许多方法都孤立地培训两种模型,并使用简单的特征组合来代表 3D 传感器数据。这种分离的培训计划可能导致亚优性性能,防止3D 任务被用于为通常本身有用的2D 任务服务。为了提供一个更加综合的方法,我们提议建立一个新的多模式任务区块网络(MTC-RCNN),利用3D 框建议改进 2D 分解预测,然后用于进一步完善 3D 框。我们表明,在 3D 模块的两个阶段中包括 2D 网络,大大改进了 2D 和 3D 任务性能。此外,为了防止3D 模块过度依赖 双头 2D 分解培训和推导计划,我们建议让 2D 3D 模块 来解释 3D 分解 3D 分解预测 3D 3D 。 我们的双级 标准 标准 标准 标准 标准 标准 将 校程 校正 校 校 校 校 校 校 校 校 度 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校