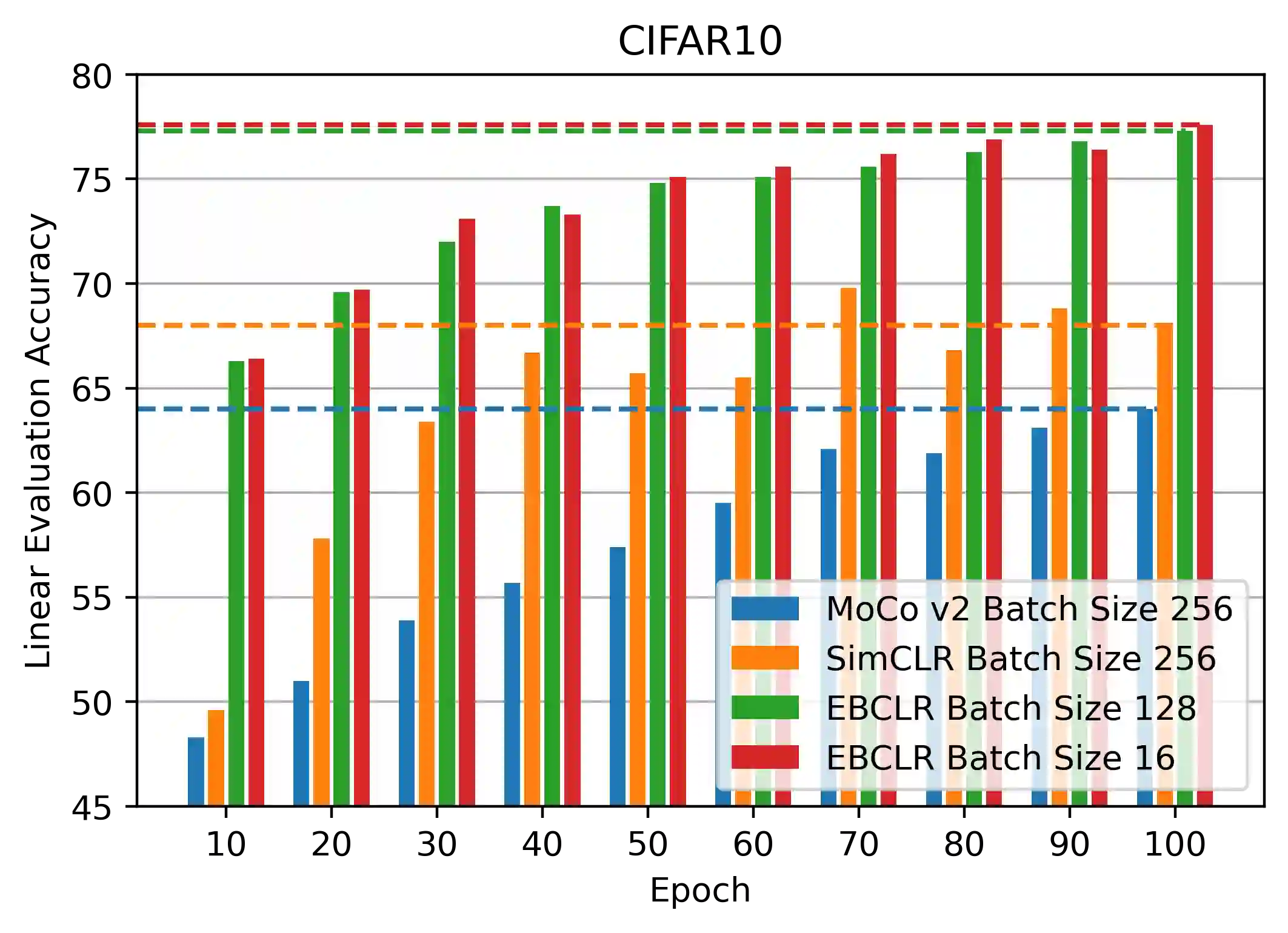
Contrastive learning is a method of learning visual representations by training Deep Neural Networks (DNNs) to increase the similarity between representations of positive pairs and reduce the similarity between representations of negative pairs. However, contrastive methods usually require large datasets with significant number of negative pairs per iteration to achieve reasonable performance on downstream tasks. To address this problem, here we propose Energy-Based Contrastive Learning (EBCLR) that combines contrastive learning with Energy-Based Models (EBMs) and can be theoretically interpreted as learning the joint distribution of positive pairs. Using a novel variant of Stochastic Gradient Langevin Dynamics (SGLD) to accelerate the training of EBCLR, we show that EBCLR is far more sample-efficient than previous self-supervised learning methods. Specifically, EBCLR shows from X4 up to X20 acceleration compared to SimCLR and MoCo v2 in terms of training epochs. Furthermore, in contrast to SimCLR, EBCLR achieves nearly the same performance with 254 negative pairs (batch size 128) and 30 negative pairs (batch size 16) per positive pair, demonstrating the robustness of EBCLR to small number of negative pairs.
翻译:通过培训深神经网络(DNNS),学习视觉表现的方法是学习深神经网络(DNNS),以增加正对代表的相似性,减少负对代表的相似性。然而,对比方法通常要求大型数据集,每迭代有大量负对,每个迭代都有大量负对,以在下游任务中取得合理业绩。为解决这一问题,我们提议采用基于能源的反竞争学习(EBCLR),将反向学习与基于能源的模式(EBMS)相结合,理论上可解释为学习正对的分布。利用Socketaritic Gradient Langevin Diritals(SGLDD)的新版本来加快EBCLR的培训,我们显示EBLR比以往的自我超强学习方法要高得多样本效率。具体地说,EBCLR的加速度从X4到X20不等,而SimCLR和MoCV2在培训中则比SMLR(EMLRRR),与S的负数接近254的负尺寸,每组为负式16。