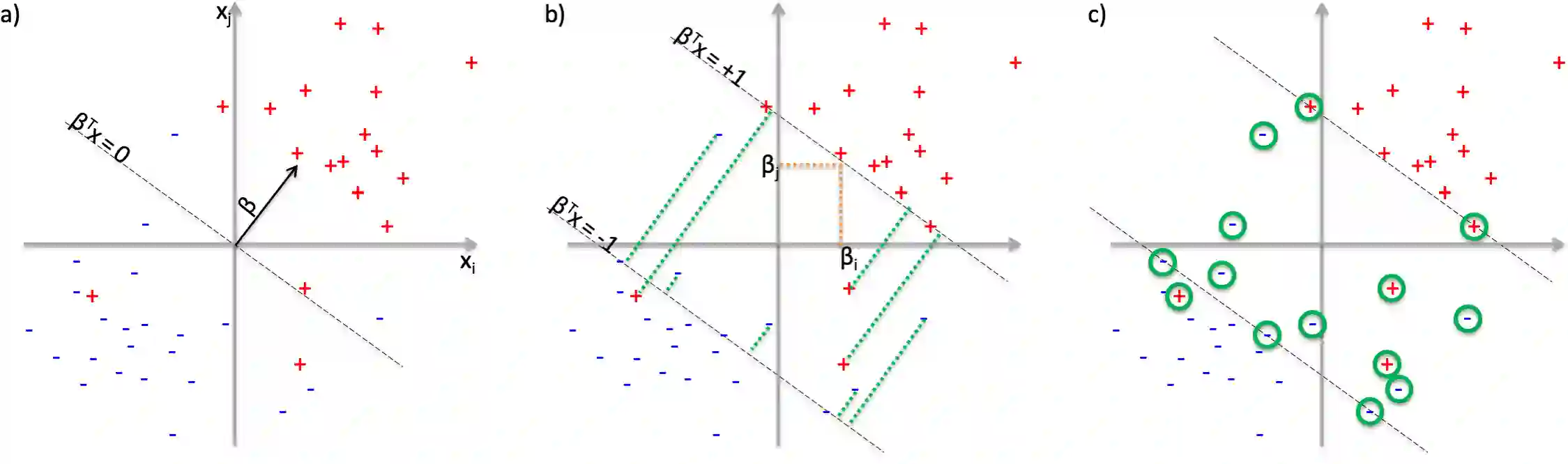
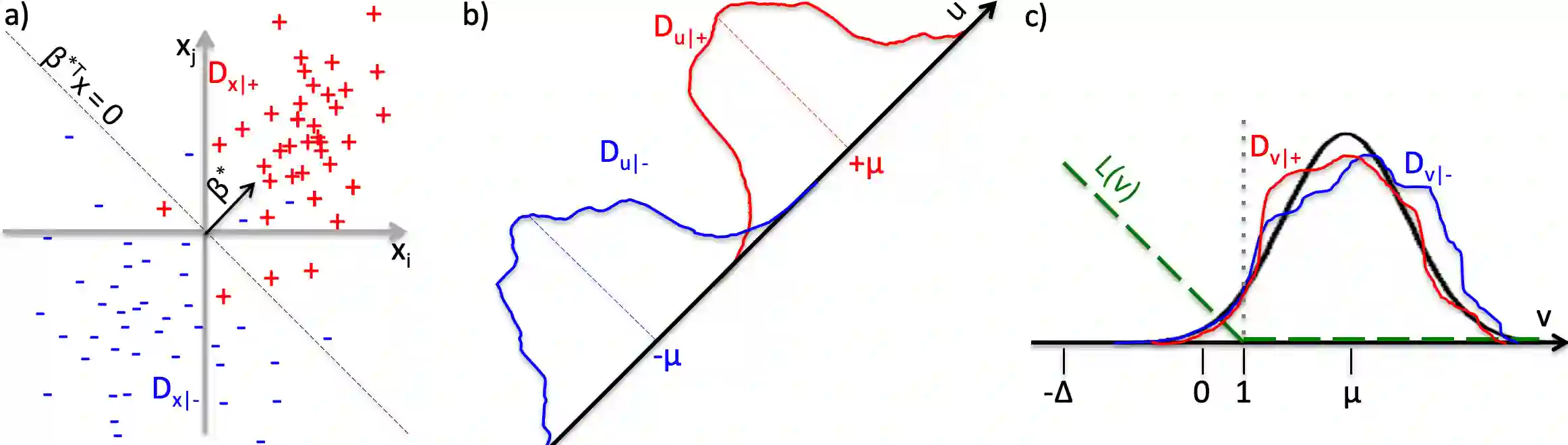
We analyze the computational complexity of Quantum Sparse Support Vector Machine, a linear classifier that minimizes the hinge loss and the $L_1$ norm of the feature weights vector and relies on a quantum linear programming solver instead of a classical solver. Sparse SVM leads to sparse models that use only a small fraction of the input features in making decisions, and is especially useful when the total number of features, $p$, approaches or exceeds the number of training samples, $m$. We prove a $\Omega(m)$ worst-case lower bound for computational complexity of any quantum training algorithm relying on black-box access to training samples; quantum sparse SVM has at least linear worst-case complexity. However, we prove that there are realistic scenarios in which a sparse linear classifier is expected to have high accuracy, and can be trained in sublinear time in terms of both the number of training samples and the number of features.
翻译:我们分析了Qantum Sparse 支持矢量机的计算复杂性。 Qantum Sparse 支持矢量机是一个线性分类器,可以最大限度地减少断链损失和特质重量矢量的1美元标准,并依赖于量子线性编程求解器而不是古典求解器。 Sparse SVM 导致模型稀少,这些模型在决策中只使用一小部分输入特征,当特性总数($p美元)、接近或超过培训样本数量($m美元)时,这些模型特别有用。 我们证明,在任何量子培训算法的计算复杂性方面,最差的值为$\ Omega(m)$(m),而任何量子培训算法依赖黑盒访问培训样本; 量子稀少的SVM 至少有线性最坏的复杂度。 然而,我们证明,有现实的假设是,在这种假设中,一个稀薄线性分类器将具有很高的准确性,并且可以在次线性时间上从培训样本的数量和特征数量上接受培训。