零基础学SVM—Support Vector Machine系列之一

本文原作者耳东陈,本文原载于作者的知乎文章。AI 研习社已获得转载授权。
如果你是一名模式识别专业的研究生,又或者你是机器学习爱好者,SVM是一个你避不开的问题。如果你只是有一堆数据需要SVM帮你处理一下,那么无论是Matlab的SVM工具箱,LIBSVM还是python框架下的SciKit Learn都可以提供方便快捷的解决方案。但如果你要追求的不仅仅是会用,还希望挑战一下“理解”这个层次,那么你就需要面对一大堆你可能从来没听过的名词,比如:非线性约束条件下的最优化、KKT条件、拉格朗日对偶、最大间隔、最优下界、核函数等等。这些名词往往会跟随一大堆天书一般的公式。如果你稍微有一点数学基础,那么单个公式你可能看得明白,但是怎么从一个公式跳到另一个公式就让人十分费解了,而最让人糊涂的其实并不是公式推导,而是如果把这些公式和你脑子里空间构想联系起来。
我本人就是上述问题的受害者之一。我翻阅了很多关于SVM的书籍和资料,但没有找到一份材料能够在公式推导、理论介绍,系统分析、变量说明、代数和几何意义的解释等方面完整地对SVM加以分析和说明的。换言之,对于普通的一年级非数学专业的研究生而言,要想看懂SVM需要搜集很多资料,然后对照阅读和深入思考,才可能比较透彻地理解SVM算法。由于我本人也在东北大学教授面向一年级硕士研究生的《模式识别技术与应用》课程,因此希望能总结出一份相对完整、简单和透彻的关于SVM算法的介绍文字,以便学生能够快速准确地理解SVM算法。
以下我会分为四个步骤对最基础的线性SVM问题加以介绍,分别是1)问题原型,2)数学模型,3)最优化求解,4)几何解释。我尽可能用最简单的语言和最基本的数学知识对上述问题进行介绍,希望能对困惑于SVM算法的学生有所帮助。
SVM算法要解决什么问题
SVM的全称是Support Vector Machine,即支持向量机,主要用于解决模式识别领域中的数据分类问题,属于有监督学习算法的一种。SVM要解决的问题可以用一个经典的二分类问题加以描述。如图1所示,红色和蓝色的二维数据点显然是可以被一条直线分开的,在模式识别领域称为线性可分问题。然而将两类数据点分开的直线显然不止一条。图1(b)和(c)分别给出了A、B两种不同的分类方案,其中黑色实线为分界线,术语称为“决策面”。每个决策面对应了一个线性分类器。虽然在目前的数据上看,这两个分类器的分类结果是一样的,但如果考虑潜在的其他数据,则两者的分类性能是有差别的。![]()
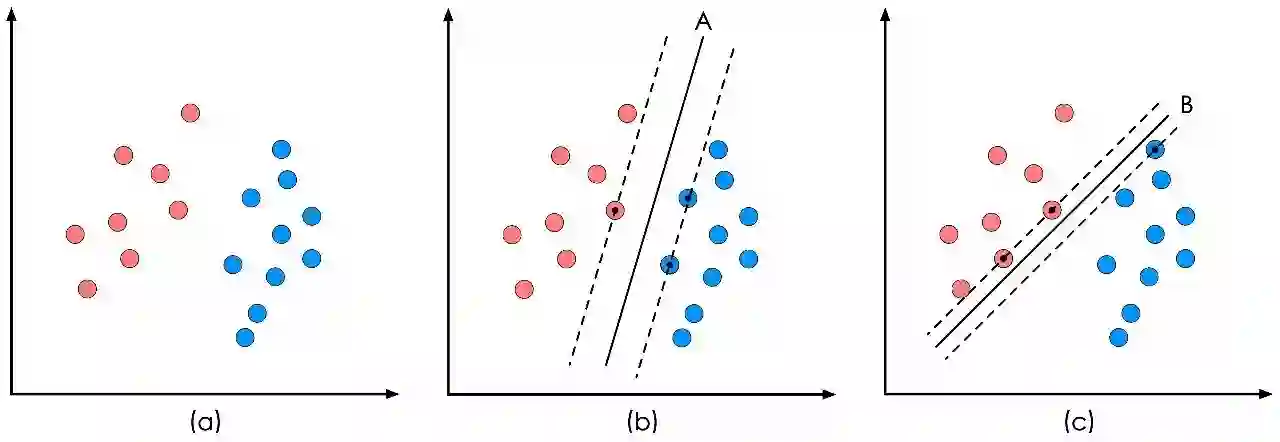
图1 二分类问题描述
SVM算法认为图1中的分类器A在性能上优于分类器B,其依据是A的分类间隔比B要大。这里涉及到第一个SVM独有的概念“分类间隔”。在保证决策面方向不变且不会出现错分样本的情况下移动决策面,会在原来的决策面两侧找到两个极限位置(越过该位置就会产生错分现象),如虚线所示。虚线的位置由决策面的方向和距离原决策面最近的几个样本的位置决定。而这两条平行虚线正中间的分界线就是在保持当前决策面方向不变的前提下的最优决策面。两条虚线之间的垂直距离就是这个最优决策面对应的分类间隔。显然每一个可能把数据集正确分开的方向都有一个最优决策面(有些方向无论如何移动决策面的位置也不可能将两类样本完全分开),而不同方向的最优决策面的分类间隔通常是不同的,那个具有“最大间隔”的决策面就是SVM要寻找的最优解。而这个真正的最优解对应的两侧虚线所穿过的样本点,就是SVM中的支持样本点,称为“支持向量”。对于图1中的数据,A决策面就是SVM寻找的最优解,而相应的三个位于虚线上的样本点在坐标系中对应的向量就叫做支持向量。
从表面上看,我们优化的对象似乎是这个决策面的方向和位置。但实际上最优决策面的方向和位置完全取决于选择哪些样本作为支持向量。而在经过漫长的公式推导后,你最终会发现,其实与线性决策面的方向和位置直接相关的参数都会被约减掉,最终结果只取决于样本点的选择结果。
到这里,我们明确了SVM算法要解决的是一个最优分类器的设计问题。既然叫作最优分类器,其本质必然是个最优化问题。所以,接下来我们要讨论的就是如何把SVM变成用数学语言描述的最优化问题模型,这就是我们在第二部分要讲的“线性SVM算法的数学建模”。
*关于“决策面”,为什么叫决策面,而不是决策线?好吧,在图1里,样本是二维空间中的点,也就是数据的维度是2,因此1维的直线可以分开它们。但是在更加一般的情况下,样本点的维度是n,则将它们分开的决策面的维度就是n-1维的超平面(可以想象一下3维空间中的点集被平面分开),所以叫“决策面”更加具有普适性,或者你可以认为直线是决策面的一个特例。
线性SVM算法的数学建模
一个最优化问题通常有两个最基本的因素:1)目标函数,也就是你希望什么东西的什么指标达到最好;2)优化对象,你期望通过改变哪些因素来使你的目标函数达到最优。在线性SVM算法中,目标函数显然就是那个“分类间隔”,而优化对象则是决策面。所以要对SVM问题进行数学建模,首先要对上述两个对象(“分类间隔”和“决策面”)进行数学描述。按照一般的思维习惯,我们先描述决策面。
2.1决策面方程
(请注意,以下的描述对于线性代数及格的同学可能显得比较啰嗦,但请你们照顾一下用高数课治疗失眠的同学们。)
请你暂时不要纠结于n维空间中的n-1维超平面这种超出正常人想象力的情景。我们就老老实实地看看二维空间中的一根直线,我们从初中就开始学习的直线方程形式很简单。
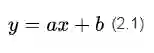
现在我们做个小小的改变,让原来的x轴变成x₁轴,y变成x₂轴,于是公式(2.1)中的直线方程会变成下面的样子
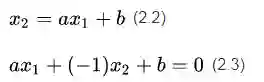
公式(2.3)的向量形式可以写成
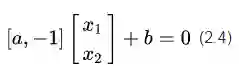
考虑到我们在等式两边乘上任何实数都不会改变等式的成立,所以我们可以写出一个更加一般的向量表达形式:
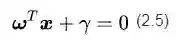
看到变量ω、x略显粗壮的身体了吗?他们是黑体,表示变量是个向量,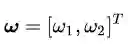
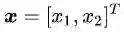
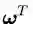
就着公式(2.5),我们再稍稍尝试深入一点。那就是探寻一下向量点积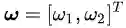
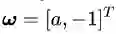
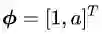
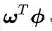
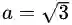
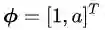
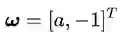
你现在是不是已经忘了我们讨论正交或者垂直的目的是什么了?那么请把你的思维从坐标系上抽出来,回到决策面方程上来。我是想告诉你向量
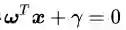
然后,在本小节的末尾,我冒昧地提示一下,在n维空间中n-1维的超平面的方程形式也是公式(2.5)的样子,只不过向量ω、x的维度从原来的2维变成了n维。如果你还是想不出来超平面的样子,也很正常。那么就请你始终记住平面上它们的样子也足够了。
到这里,我们花了很多篇幅描述一个很简单的超平面方程(其实只是个直线方程),这里真正有价值的是这个控制方向的参数ω。接下来,你会有很长一段时间要思考它到底是个什么东西,对于SVM产生了怎样的影响。
2.2 分类“间隔”的计算模型
我们在第一章里介绍过分类间隔的定义及其直观的几何意义。间隔的大小实际上就是支持向量对应的样本点到决策面的距离的二倍,如图2所示。
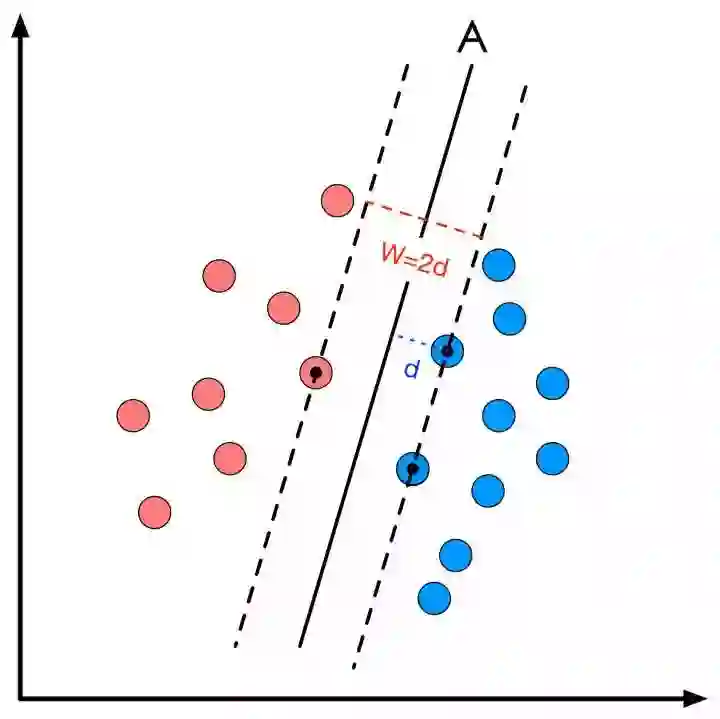
图2 分类间隔计算
所以分类间隔计算似乎相当简单,无非就是点到直线的距离公式。如果你想要回忆高中老师在黑板上推导的过程,可以随便在百度文库里搜索关键词“点到直线距离推导公式”,你会得到至少6、7种推导方法。但这里,请原谅我给出一个简单的公式如下:
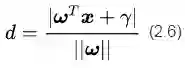
这里||ω||是向量ω的模,表示在空间中向量的长度,
但问题当然不会这么简单,我们还需要面对一连串令人头疼的麻烦。
2.3 约束条件
接着2.2节的结尾,我们讨论一下究竟还有哪些麻烦没有解决:
1.并不是所有的方向都存在能够实现100%正确分类的决策面,我们如何判断一条直线是否能够将所有的样本点都正确分类?
2.即便找到了正确的决策面方向,还要注意决策面的位置应该在间隔区域的中轴线上,所以用来确定决策面位置的截距γ也不能自由的优化,而是受到决策面方向和样本点分布的约束。
3.即便取到了合适的方向和截距,公式(2.6)里面的x不是随随便便的一个样本点,而是支持向量对应的样本点。对于一个给定的决策面,我们该如何找到对应的支持向量?
以上三条麻烦的本质是“约束条件”,也就是说我们要优化的变量的取值范围受到了限制和约束。事实上约束条件一直是最优化问题里最让人头疼的东西。但既然我们已经论证了这些约束条件确实存在,就不得不用数学语言对他们进行描述。尽管上面看起来是3条约束,但SVM算法通过一些巧妙的小技巧,将这三条约束条件融合在了一个不等式里面。
我们首先考虑一个决策面是否能够将所有的样本都正确分类的约束。图2中的样本点分成两类(红色和蓝色),我们为每个样本点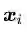
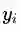

如果我们的决策面方程能够完全正确地对图2中的样本点进行分类,就会满足下面的公式
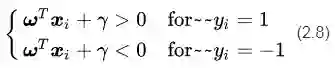
如果我们要求再高一点,假设决策面正好处于间隔区域的中轴线上,并且相应的支持向量对应的样本点到决策面的距离为d,那么公式(2.8)就可以进一步写成:
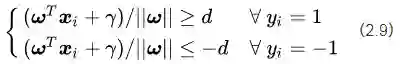
符号
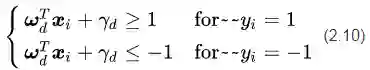
其中
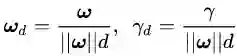
把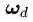
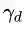
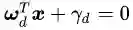
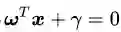
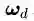
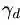
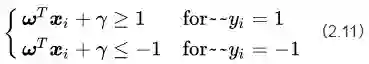
公式(2.11)可以认为是SVM优化问题的约束条件的基本描述。
2.4 线性SVM优化问题基本描述
公式(2.11)里面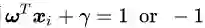
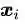
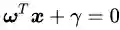
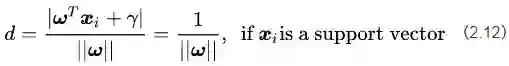
公式(2.12)的几何意义就是,支持向量样本点到决策面方程的距离就是1/||ω||。我们原来的任务是找到一组参数ω、γ使得分类间隔W=2d最大化,根据公式(2.12)就可以转变为||ω||的最小化问题,也等效于1/2||ω||²的最小化问题。我们之所以要在||ω||上加上平方和1/2的系数,是为了以后进行最优化的过程中对目标函数求导时比较方便,但这绝不影响最优化问题最后的解。
另外我们还可以尝试将公式(2.11)给出的约束条件进一步在形式上精练,把类别标签
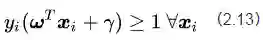
好了,到这里我们可以给出线性SVM最优化问题的数学描述了:
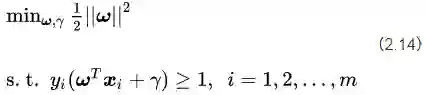
这里m是样本点的总个数,缩写s. t. 表示“Subject to”,是“服从某某条件”的意思。公式(2.14)描述的是一个典型的不等式约束条件下的二次型函数优化问题,同时也是支持向量机的基本数学模型。(此时此刻,你也许会回头看2.3节我们提出的三个约束问题,思考它们在公式2.14的约束条件中是否已经得到了充分的体现。但我不建议你现在就这么做,因为2.14采用了一种比较含蓄的方式表示这些约束条件,所以你即便现在不理解也没关系,后面随着推导的深入,这些问题会一点点露出真容。)
接下来,我们将在第三章讨论大多数同学比较陌生的问题:如何利用最优化技术求解公式(2.14)描述的问题。哪些令人望而生畏的术语,凸二次优化、拉格朗日对偶、KKT条件、鞍点等等,大多出现在这个部分。全面理解和熟练掌握这些概念当然不容易,但如果你的目的主要是了解这些技术如何在SVM问题进行应用的,那么阅读过下面一章后,你有很大的机会可以比较直观地理解这些问题。
*一点小建议,读到这里,你可以试着在纸上随便画一些点,然后尝试用SVM的思想手动画线将两类不同的点分开。你会发现大多数情况下,你会先画一条可以成功分开两类样本点的直线,然后你会在你的脑海中想象去旋转这条线,旋转到某个角度,你就会下意识的停下来,因为如果再旋转下去,就找不到能够成功将两类点分开的直线了。这个过程就是对直线方向的优化过程。对于有些问题,你会发现SVM的最优解往往出现在不能再旋转下去的边界位置,这就是约束条件的边界,对比我们提到的等式约束条件,你会对代数公式与几何想象之间的关系得到一些相对直观的印象。
(未完待续)
更多SVM相关文章
开发者自述:我是怎样理解支持向量机(SVM)与神经网络的
最经典的SVM算法在Spark上实现,这里有一份详尽的开发教程(含代码)
机器学习经典算法优缺点总结
十大必须掌握的机器学习算法,你都知道了吗?
不可错过的TensorFlow工具包,内含8大算法,即去即用!


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
机器学习之线性代数及矩阵论
▼▼▼



