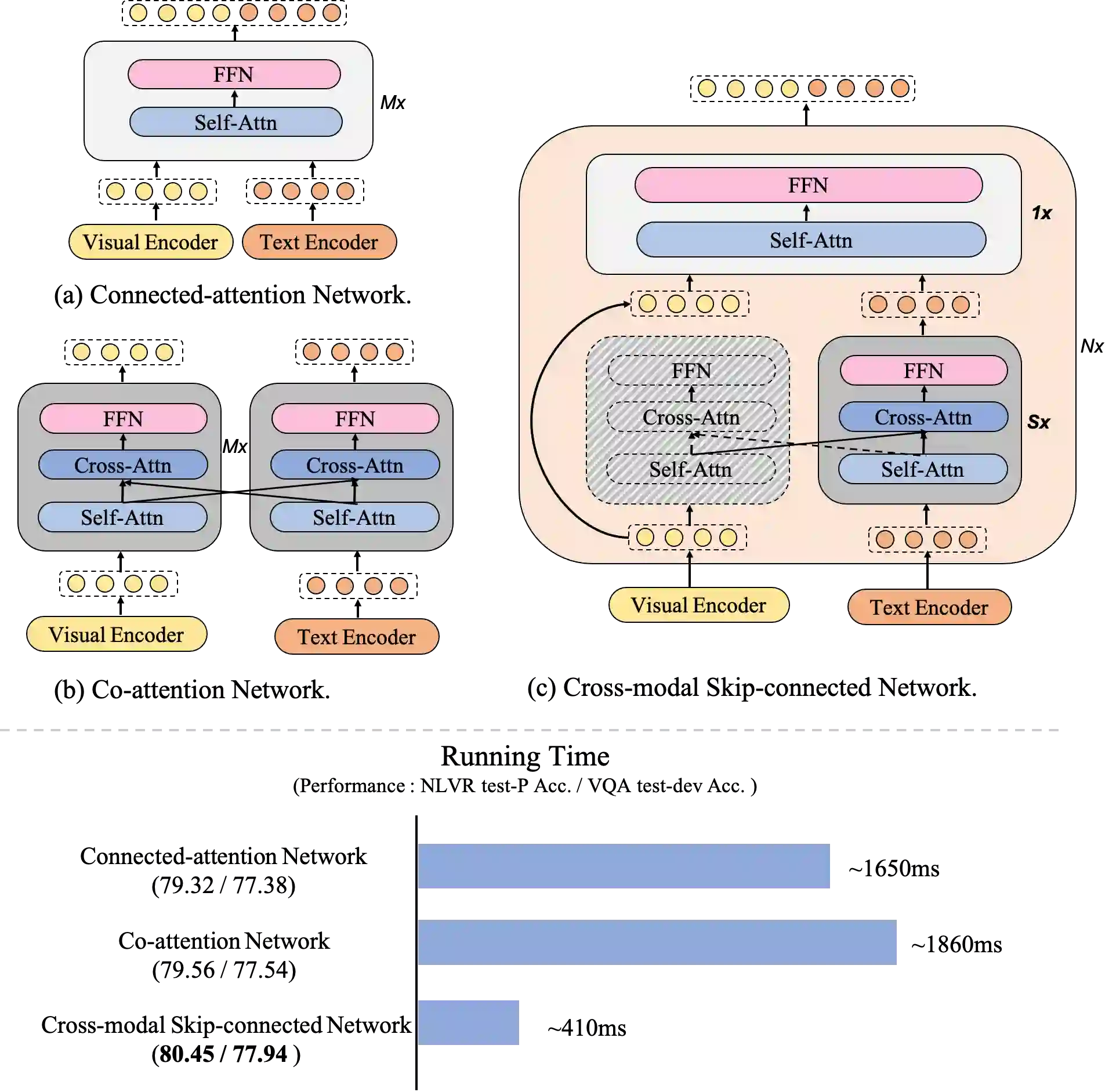
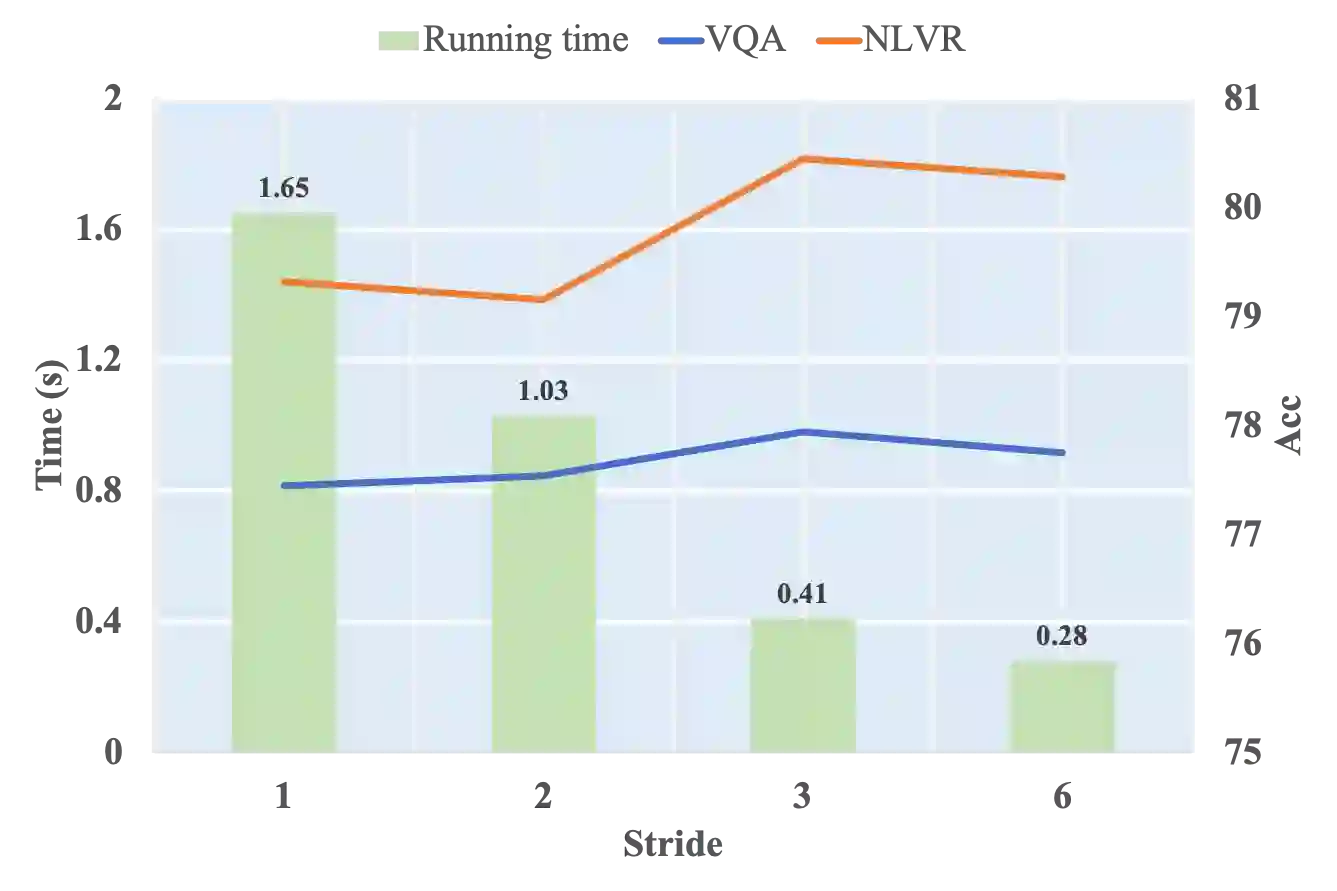
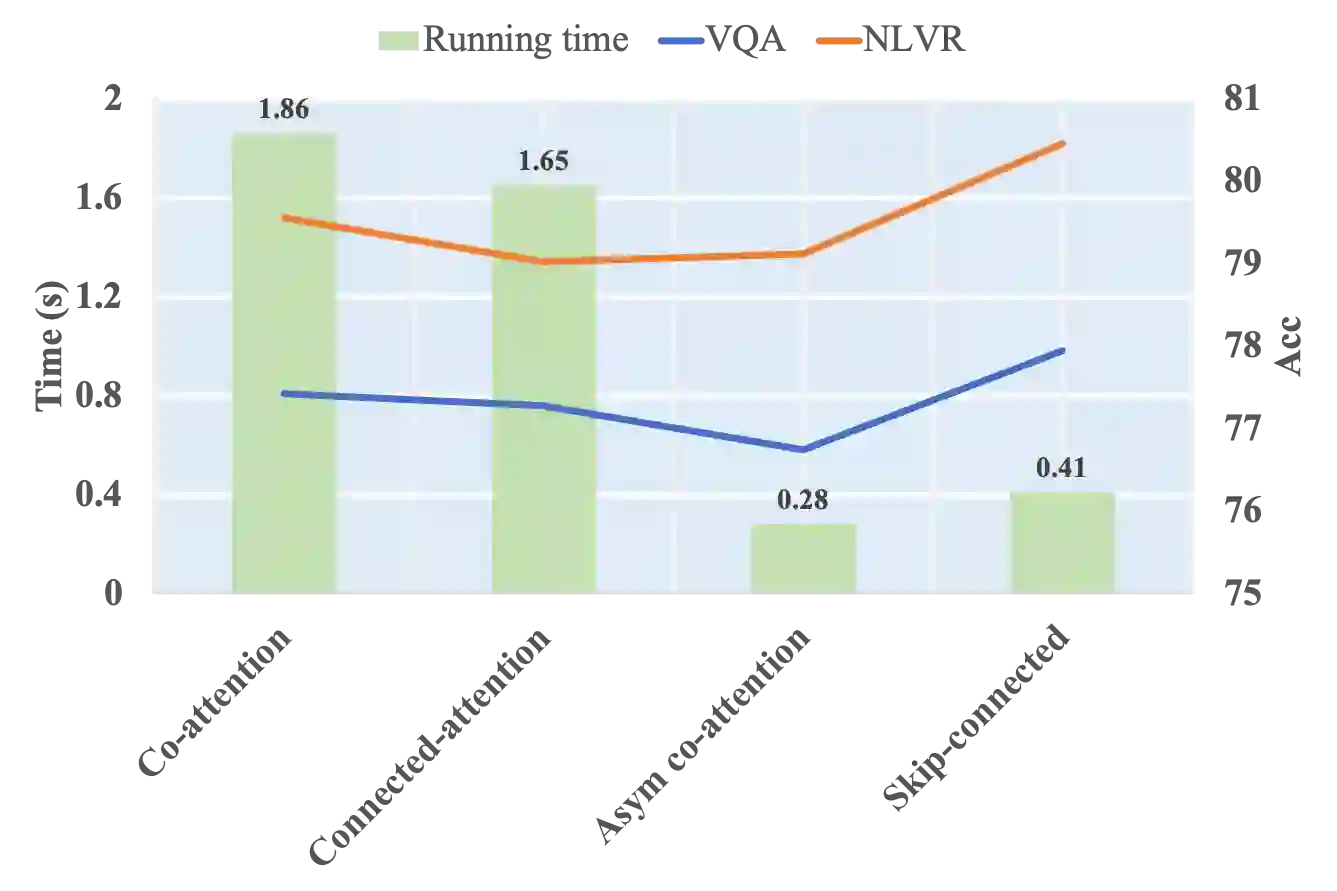
Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
翻译:大规模预先培训的基础模型是建立人工智能系统的新兴范例,可以迅速适应广泛的下游任务,本文件介绍了MPLUG,这是跨模式理解和生成的一个新的视觉语言基础模型;大多数经过培训的现有模型都存在由于跨模式一致的长视序列带来的计算效率低和信息不对称问题;为解决这些问题,MPLUG引入了一个具有新颖跨模式跳动功能的高效视觉语言结构,从而创建了跨层次捷径,跳过一定的层,供视觉一侧完全自省使用。MPLUG是经过事先培训的大型图像配对端对端端端到端,既具有歧视性,又具有基因化目标。它实现了关于广泛视觉语言下游任务的最新结果,例如图像字幕、图像文本检索、视觉地面和视觉回答。 mPLUG还表明在直接转移到多种视频语言任务时,零点可转移性很强。