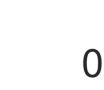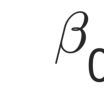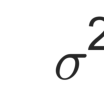In the analysis of data sets consisting of (X, Y)-pairs, a tacit assumption is that each pair corresponds to the same observation unit. If, however, such pairs are obtained via record linkage of two files, this assumption can be violated as a result of mismatch error rooting, for example, in the lack of reliable identifiers in the two files. Recently, there has been a surge of interest in this setting under the term "Shuffled data" in which the underlying correct pairing of (X, Y)-pairs is represented via an unknown index permutation. Explicit modeling of the permutation tends to be associated with substantial overfitting, prompting the need for suitable methods of regularization. In this paper, we propose a flexible exponential family prior on the permutation group for this purpose that can be used to integrate various structures such as sparse and locally constrained shuffling. This prior turns out to be conjugate for canonical shuffled data problems in which the likelihood conditional on a fixed permutation can be expressed as product over the corresponding (X,Y)-pairs. Inference is based on the EM algorithm in which the intractable E-step is approximated by the Fisher-Yates algorithm. The M-step is shown to admit a significant reduction from $n^2$ to $n$ terms if the likelihood of (X,Y)-pairs has exponential family form as in the case of generalized linear models. Comparisons on synthetic and real data show that the proposed approach compares favorably to competing methods.
翻译:在分析由(X、Y)和(X、Y)至(pair)组成的数据集时,隐含的假设是,每对对对应同一观察单位。但是,如果通过两个文件的记录链接获得这些对对配,则由于不匹配的错误根基,例如,两个文件中缺乏可靠的识别器,这一假设可能受到侵犯。最近,在“合成数据”这一术语下,对这一设置的兴趣激增,其基础正确对齐(X、Y)至(pairs)之间的对齐通过未知的指数调整方式表示。调整的模型往往与相当的过度配对相联系,从而促使需要适当的规范化方法。在本文件中,我们提议在调整组中,为了这个目的,可以使用一个灵活的指数式组合来整合各种结构,例如:稀少和本地受限的抖动。在“合成数据”这一术语中,以固定的调和(X、Y)至相应(X)至(美元)的直线式格式的偏移的可能性表示成产品。在“Y-stepreal-al2”的比较中,其直径比值以亚(roal-iral-iralalalalal)法显示,其直径的缩值为正变为正变的缩成。