【清华大学NLP】预训练语言模型(PLM)必读论文清单,附论文PDF、源码和模型链接
【导读】近两年来,ELMO、BERT等预训练语言模型(PLM)在多项任务中刷新了榜单,引起了学术界和工业界的大量关注。本文介绍清华大学NLP给出的预训练语言模型必读论文清单,包含论文的PDF链接、源码和模型等。
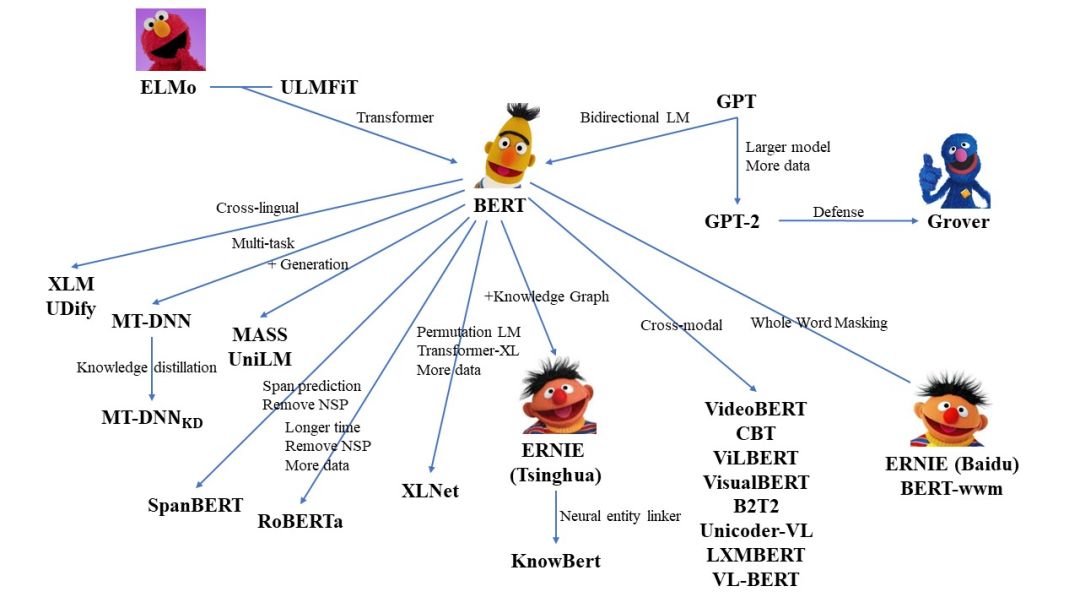
清华大学NLP在Github项目thunlp/PLMpapers中提供了预训练语言模型必读论文清单,包含了论文的PDF链接、源码和模型等,具体清单如下:
模型:
Deep contextualized word representations. Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee and Luke Zettlemoyer. NAACL 2018.
论文:
https://arxiv.org/pdf/1802.05365.pdf工程:
https://allennlp.org/elmo (ELMo)Universal Language Model Fine-tuning for Text Classification. Jeremy Howard and Sebastian Ruder. ACL 2018.
论文:
https://www.aclweb.org/anthology/P18-1031工程:
http://nlp.fast.ai/category/classification.html (ULMFiT)Improving Language Understanding by Generative Pre-Training. Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever. Preprint.
论文:
https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf工程:
https://openai.com/blog/language-unsupervised/ (GPT)BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. NAACL 2019.
论文:
https://arxiv.org/pdf/1810.04805.pdf代码+模型:
https://github.com/google-research/bertLanguage Models are Unsupervised Multitask Learners. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever. Preprint.
论文:
https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf代码:
https://github.com/openai/gpt-2 (GPT-2)ERNIE: Enhanced Language Representation with Informative Entities. Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun and Qun Liu. ACL2019.
论文:
https://www.aclweb.org/anthology/P19-1139代码+模型:
https://github.com/thunlp/ERNIE (ERNIE (Tsinghua) )ERNIE: Enhanced Representation through Knowledge Integration. Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian and Hua Wu. Preprint.
论文:
https://arxiv.org/pdf/1904.09223.pdf代码:
https://github.com/PaddlePaddle/ERNIE/tree/develop/ERNIE (ERNIE (Baidu) )Defending Against Neural Fake News. Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, Yejin Choi. NeurIPS.
论文:
https://arxiv.org/pdf/1905.12616.pdf工程:
https://rowanzellers.com/grover/ (Grover)Cross-lingual Language Model Pretraining. Guillaume Lample, Alexis Conneau. NeurIPS2019.
论文:
https://arxiv.org/pdf/1901.07291.pdf代码+模型:
https://github.com/facebookresearch/XLM (XLM)Multi-Task Deep Neural Networks for Natural Language Understanding. Xiaodong Liu, Pengcheng He, Weizhu Chen, Jianfeng Gao. ACL2019.
论文:
https://www.aclweb.org/anthology/P19-1441代码+模型:
https://github.com/namisan/mt-dnn (MT-DNN)MASS: Masked Sequence to Sequence Pre-training for Language Generation. Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu. ICML2019.
论文:
https://arxiv.org/pdf/1905.02450.pdf代码+模型:
https://github.com/microsoft/MASSUnified Language Model Pre-training for Natural Language Understanding and Generation. Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon. Preprint.
论文:
https://arxiv.org/pdf/1905.03197.pdf (UniLM)XLNet: Generalized Autoregressive Pretraining for Language Understanding. Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le. NeurIPS2019.
论文:
https://arxiv.org/pdf/1906.08237.pdf代码+模型:
https://github.com/zihangdai/xlnetRoBERTa: A Robustly Optimized BERT Pretraining Approach. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. Preprint.
论文:
https://arxiv.org/pdf/1907.11692.pdf代码+模型:
https://github.com/pytorch/fairseqSpanBERT: Improving Pre-training by Representing and Predicting Spans. Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, Omer Levy. Preprint.
论文:
https://arxiv.org/pdf/1907.10529.pdf代码+模型:
https://github.com/facebookresearch/SpanBERTKnowledge Enhanced Contextual Word Representations. Matthew E. Peters, Mark Neumann, Robert L. Logan IV, Roy Schwartz, Vidur Joshi, Sameer Singh, Noah A. Smith. EMNLP2019.
论文:
https://arxiv.org/pdf/1909.04164.pdf (KnowBert)VisualBERT: A Simple and Performant Baseline for Vision and Language. Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang. Preprint.
论文:
https://arxiv.org/pdf/1908.03557.pdf代码+模型:
https://github.com/uclanlp/visualbertViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee. NeurIPS.
论文:
https://arxiv.org/pdf/1908.02265.pdf代码+模型:
https://github.com/jiasenlu/vilbert_betaVideoBERT: A Joint Model for Video and Language Representation Learning. Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, Cordelia Schmid. ICCV2019.
论文:
https://arxiv.org/pdf/1904.01766.pdfLXMERT: Learning Cross-Modality Encoder Representations from Transformers. Hao Tan, Mohit Bansal. EMNLP2019.
论文:
https://arxiv.org/pdf/1908.07490.pdf代码+模型:
https://github.com/airsplay/lxmertVL-BERT: Pre-training of Generic Visual-Linguistic Representations. Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. Preprint.
论文:
https://arxiv.org/pdf/1908.08530.pdfUnicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training. Gen Li, Nan Duan, Yuejian Fang, Ming Gong, Daxin Jiang, Ming Zhou. Preprint.
论文:
https://arxiv.org/pdf/1908.06066.pdfK-BERT: Enabling Language Representation with Knowledge Graph. Weijie Liu, Peng Zhou, Zhe Zhao, Zhiruo Wang, Qi Ju, Haotang Deng, Ping Wang. Preprint.
论文:
https://arxiv.org/pdf/1909.07606.pdfFusion of Detected Objects in Text for Visual Question Answering. Chris Alberti, Jeffrey Ling, Michael Collins, David Reitter. EMNLP2019.
论文:
https://arxiv.org/pdf/1908.05054.pdf (B2T2)Contrastive Bidirectional Transformer for Temporal Representation Learning. Chen Sun, Fabien Baradel, Kevin Murphy, Cordelia Schmid. Preprint.
论文:
https://arxiv.org/pdf/1906.05743.pdf (CBT)ERNIE 2.0: A Continual Pre-training Framework for Language Understanding. Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Hao Tian, Hua Wu, Haifeng Wang. Preprint.
论文:
https://arxiv.org/pdf/1907.12412v1.pdf代码:
https://github.com/PaddlePaddle/ERNIE/blob/develop/README.md75 Languages, 1 Model: Parsing Universal Dependencies Universally. Dan Kondratyuk, Milan Straka. EMNLP2019.
论文:
https://arxiv.org/pdf/1904.02099.pdf代码+模型:
https://github.com/hyperparticle/udify (UDify)Pre-Training with Whole Word Masking for Chinese BERT. Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu. Preprint.
论文:
https://arxiv.org/pdf/1906.08101.pdf代码+模型:
https://github.com/ymcui/Chinese-BERT-wwm/blob/master/README_EN.md (Chinese-BERT-wwm)
知识蒸馏和模型压缩:
TinyBERT: Distilling BERT for Natural Language Understanding. Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu.
论文:
https://arxiv.org/pdf/1909.10351v1.pdfDistilling Task-Specific Knowledge from BERT into Simple Neural Networks. Raphael Tang, Yao Lu, Linqing Liu, Lili Mou, Olga Vechtomova, Jimmy Lin. Preprint.
论文:
https://arxiv.org/pdf/1903.12136.pdfPatient Knowledge Distillation for BERT Model Compression. Siqi Sun, Yu Cheng, Zhe Gan, Jingjing Liu. EMNLP2019.
论文:
https://arxiv.org/pdf/1908.09355.pdf代码:
https://github.com/intersun/PKD-for-BERT-Model-CompressionModel Compression with Multi-Task Knowledge Distillation for Web-scale Question Answering System. Ze Yang, Linjun Shou, Ming Gong, Wutao Lin, Daxin Jiang. Preprint.
论文:
https://arxiv.org/pdf/1904.09636.pdfPANLP at MEDIQA 2019: Pre-trained Language Models, Transfer Learning and Knowledge Distillation. Wei Zhu, Xiaofeng Zhou, Keqiang Wang, Xun Luo, Xiepeng Li, Yuan Ni, Guotong Xie. The 18th BioNLP workshop.
论文:
https://www.aclweb.org/anthology/W19-5040Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding. Xiaodong Liu, Pengcheng He, Weizhu Chen, Jianfeng Gao. Preprint.
论文:
https://arxiv.org/pdf/1904.09482.pdf代码+模型:
https://github.com/namisan/mt-dnnWell-Read Students Learn Better: The Impact of Student Initialization on Knowledge Distillation. Iulia Turc, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. Preprint.
论文:
https://arxiv.org/pdf/1908.08962.pdfSmall and Practical BERT Models for Sequence Labeling. Henry Tsai, Jason Riesa, Melvin Johnson, Naveen Arivazhagan, Xin Li, Amelia Archer. EMNLP2019.
论文:
https://arxiv.org/pdf/1909.00100.pdfQ-BERT: Hessian Based Ultra Low Precision Quantization of BERT. Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W. Mahoney, Kurt Keutzer. Preprint.
论文:
https://arxiv.org/pdf/1909.05840.pdfALBERT: A Lite BERT for Self-supervised Learning of Language Representations. Anonymous authors. ICLR2020 under review.
论文:
https://openreview.net/pdf?id=H1eA7AEtvS
分析:
Revealing the Dark Secrets of BERT. Olga Kovaleva, Alexey Romanov, Anna Rogers, Anna Rumshisky. EMNLP2019.
论文:
https://arxiv.org/abs/1908.08593How Does BERT Answer Questions? A Layer-Wise Analysis of Transformer Representations. Betty van Aken, Benjamin Winter, Alexander Löser, Felix A. Gers. CIKM2019.
论文:
https://arxiv.org/pdf/1909.04925.pdfAre Sixteen Heads Really Better than One?. Paul Michel, Omer Levy, Graham Neubig. Preprint.
论文:
https://arxiv.org/pdf/1905.10650.pdf代码:
https://github.com/pmichel31415/are-16-heads-really-better-than-1Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. Di Jin, Zhijing Jin, Joey Tianyi Zhou, Peter Szolovits. Preprint.
论文:
https://arxiv.org/pdf/1907.11932.pdf代码:
https://github.com/jind11/TextFoolerBERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model. Alex Wang, Kyunghyun Cho. NeuralGen2019.
论文:
https://arxiv.org/pdf/1902.04094.pdf代码:
https://github.com/nyu-dl/bert-genLinguistic Knowledge and Transferability of Contextual Representations. Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, Noah A. Smith. NAACL2019.
论文:
https://www.aclweb.org/anthology/N19-1112What Does BERT Look At? An Analysis of BERT's Attention. Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning. BlackBoxNLP2019.
论文:
https://arxiv.org/pdf/1906.04341.pdf代码:
https://github.com/clarkkev/attention-analysisOpen Sesame: Getting Inside BERT's Linguistic Knowledge. Yongjie Lin, Yi Chern Tan, Robert Frank. BlackBoxNLP2019.
论文:
https://arxiv.org/pdf/1906.01698.pdf代码:
https://github.com/yongjie-lin/bert-opensesameAnalyzing the Structure of Attention in a Transformer Language Model. Jesse Vig, Yonatan Belinkov. BlackBoxNLP2019.
论文:
https://arxiv.org/pdf/1906.04284.pdfBlackbox meets blackbox: Representational Similarity and Stability Analysis of Neural Language Models and Brains. Samira Abnar, Lisa Beinborn, Rochelle Choenni, Willem Zuidema. BlackBoxNLP2019.
论文:
https://arxiv.org/pdf/1906.01539.pdfBERT Rediscovers the Classical NLP Pipeline. Ian Tenney, Dipanjan Das, Ellie Pavlick. ACL2019.
论文:
https://www.aclweb.org/anthology/P19-1452How multilingual is Multilingual BERT?. Telmo Pires, Eva Schlinger, Dan Garrette. ACL2019.
论文:
https://www.aclweb.org/anthology/P19-1493What Does BERT Learn about the Structure of Language?. Ganesh Jawahar, Benoît Sagot, Djamé Seddah. ACL2019.
论文:
https://www.aclweb.org/anthology/P19-1356Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT. Shijie Wu, Mark Dredze. EMNLP2019.
论文:
https://arxiv.org/pdf/1904.09077.pdfHow Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. Kawin Ethayarajh. EMNLP2019.
论文:
https://arxiv.org/pdf/1909.00512.pdfProbing Neural Network Comprehension of Natural Language Arguments. Timothy Niven, Hung-Yu Kao. ACL2019.
论文:
https://www.aclweb.org/anthology/P19-1459代码:
https://github.com/IKMLab/arct2Universal Adversarial Triggers for Attacking and Analyzing NLP. Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, Sameer Singh. EMNLP2019.
论文:
https://arxiv.org/pdf/1908.07125.pdf代码:
https://github.com/Eric-Wallace/universal-triggersThe Bottom-up Evolution of Representations in the Transformer: A Study with Machine Translation and Language Modeling Objectives. Elena Voita, Rico Sennrich, Ivan Titov. EMNLP2019.
论文:
https://arxiv.org/pdf/1909.01380.pdfDo NLP Models Know Numbers? Probing Numeracy in Embeddings. Eric Wallace, Yizhong Wang, Sujian Li, Sameer Singh, Matt Gardner. EMNLP2019.
论文:
https://arxiv.org/pdf/1909.07940.pdfInvestigating BERT's Knowledge of Language: Five Analysis Methods with NPIs. Alex Warstadt, Yu Cao, Ioana Grosu, Wei Peng, Hagen Blix, Yining Nie, Anna Alsop, Shikha Bordia, Haokun Liu, Alicia Parrish, Sheng-Fu Wang, Jason Phang, Anhad Mohananey, Phu Mon Htut, Paloma Jeretič, Samuel R. Bowman. EMNLP2019.
论文:
https://arxiv.org/pdf/1909.02597.pdf代码:
https://github.com/alexwarstadt/data_generationVisualizing and Understanding the Effectiveness of BERT. Yaru Hao, Li Dong, Furu Wei, Ke Xu. EMNLP2019.
论文:
https://arxiv.org/pdf/1908.05620.pdfVisualizing and Measuring the Geometry of BERT. Andy Coenen, Emily Reif, Ann Yuan, Been Kim, Adam Pearce, Fernanda Viégas, Martin Wattenberg. NeurIPS2019.
论文:
https://arxiv.org/pdf/1906.02715.pdfOn the Validity of Self-Attention as Explanation in Transformer Models. Gino Brunner, Yang Liu, Damián Pascual, Oliver Richter, Roger Wattenhofer. Preprint.
论文:
https://arxiv.org/pdf/1908.04211.pdfTransformer Dissection: An Unified Understanding for Transformer's Attention via the Lens of Kernel. Yao-Hung Hubert Tsai, Shaojie Bai, Makoto Yamada, Louis-Philippe Morency, Ruslan Salakhutdinov. EMNLP2019.
论文:
https://arxiv.org/pdf/1908.11775.pdfLanguage Models as Knowledge Bases? Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel. EMNLP2019.
论文:
https://arxiv.org/pdf/1909.01066.pdf代码:
https://github.com/facebookresearch/LAMA
参考链接:
https://github.com/thunlp/PLMpapers
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




