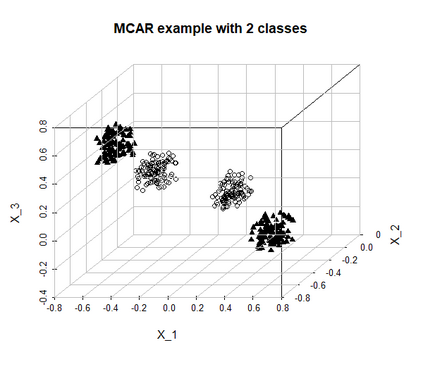
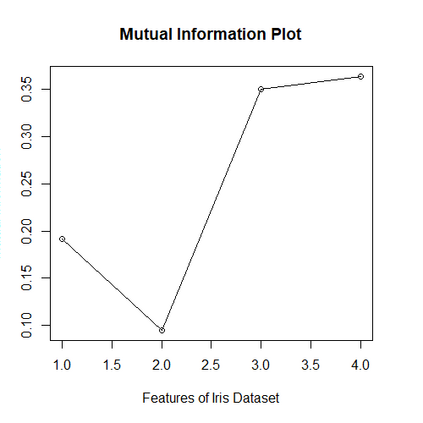
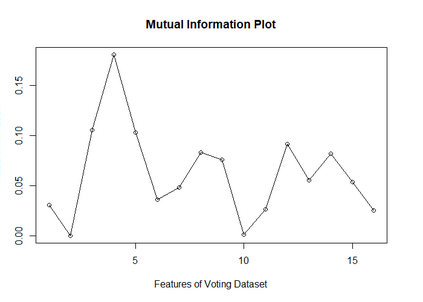
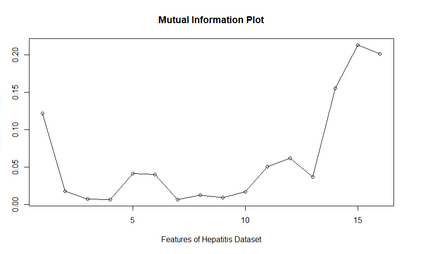
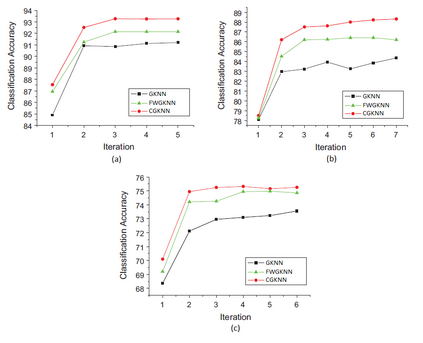
Imputation of missing data is a common application in various classification problems where the feature training matrix has missingness. A widely used solution to this imputation problem is based on the lazy learning technique, $k$-nearest neighbor (kNN) approach. However, most of the previous work on missing data does not take into account the presence of the class label in the classification problem. Also, existing kNN imputation methods use variants of Minkowski distance as a measure of distance, which does not work well with heterogeneous data. In this paper, we propose a novel iterative kNN imputation technique based on class weighted grey distance between the missing datum and all the training data. Grey distance works well in heterogeneous data with missing instances. The distance is weighted by Mutual Information (MI) which is a measure of feature relevance between the features and the class label. This ensures that the imputation of the training data is directed towards improving classification performance. This class weighted grey kNN imputation algorithm demonstrates improved performance when compared to other kNN imputation algorithms, as well as standard imputation algorithms such as MICE and missForest, in imputation and classification problems. These problems are based on simulated scenarios and UCI datasets with various rates of missingness.
翻译:在特征培训矩阵缺失的情况下,对缺失数据进行估计是各种分类问题的一种常见应用。对于这一估算问题,广泛使用的一种解决办法是基于懒惰的学习技巧,即$k$最近邻居(kNN)的方法。然而,以往关于缺失数据的大部分工作没有考虑到分类问题中存在分类标签的问题。此外,现有的 kNN指数估算方法将Minkowski距离的变量作为一种测量距离的尺度,这与混杂数据不起作用。在本文中,我们建议根据缺失数据与所有培训数据之间的等级加权灰色距离,采用新的迭代式 kNNN指数计算技术。灰色距离在缺少的情况下,在混杂数据方面运作良好。“相互信息”(MI)对疏远进行了加权,这是测量特征和类标签之间特征相关性的一个尺度。这确保了培训数据的估算用于改进分类性能。这一类加权的灰色 kNNN 估算算法表明,与其他 kNN 估算算法相比,业绩有所改善,以及标准化算法,如MICE和误差(IMIC)的模拟率和问题。