大型语言模型(LLMs)正在推动分子发现范式的转变,使研究人员能够通过自然语言、符号表示等方式,在化学空间中实现文本引导式交互,并正逐步扩展至多模态输入的融合应用。为推动“LLM赋能分子发现”这一新兴交叉领域的发展,本文对LLM在两个核心任务——分子生成与分子优化——中的应用进行了最新且前瞻性的综述。 我们提出了面向上述任务的系统分类方法(taxonomy),并基于此对各类代表性技术进行了分析,重点展示了LLM在不同学习范式下的应用方式与能力体现。此外,本文还汇总了该领域常用的数据集与评估标准,以便研究者快速入门与比较。 最后,我们讨论了当前面临的关键挑战与未来发展方向,旨在将本综述打造为LLM与分子科学交叉领域研究人员的重要参考资源。 持续更新的阅读资源列表请访问: https://github.com/REAL-Lab-NU/Awesome-LLM-Centric-Molecular-Discovery
1 引言
分子设计与优化是多个科学领域的核心问题,包括药物发现(Zheng 等,2024)、材料科学(Grandi 等,2025)和合成化学(Lu 等,2024;Wang 等,2025)。然而,由于化学空间庞大且结构复杂,在保证化学有效性与结构可行性的同时发现具备理想性质的新型化合物仍是一项极具挑战性的任务(Zheng 等,2024;Yu 等,2025)。为实现这一目标,过去已有多种计算方法被提出,从变分自编码器(VAE)[Gómez-Bombarelli 等,2018]、生成对抗网络(GAN)[De Cao 和 Kipf,2018] 到基于Transformer的模型 [Edwards 等,2022]。然而,这些传统方法在生成高质量、多样化且具有可合成性的分子方面仍面临诸多限制(Ramos 等,2025;Sun 等,2025)。
近年来,**大型语言模型(LLMs)**在应对这些挑战方面展现出强大能力,并迅速吸引了广泛研究关注(Zheng 等,2024)。作为基础模型,LLMs拥有数十亿参数,具备诸如复杂推理、指令理解以及上下文学习等涌现能力,这些能力得益于其在多样化大规模数据集上的预训练(Brown 等,2020;Wei 等,2022a)。因此,LLMs不仅能够泛化至各种化学问题,还可以通过微调进一步适应特定任务。这些独特优势使LLMs成为探索化学空间、加速分子发现的全新范式。
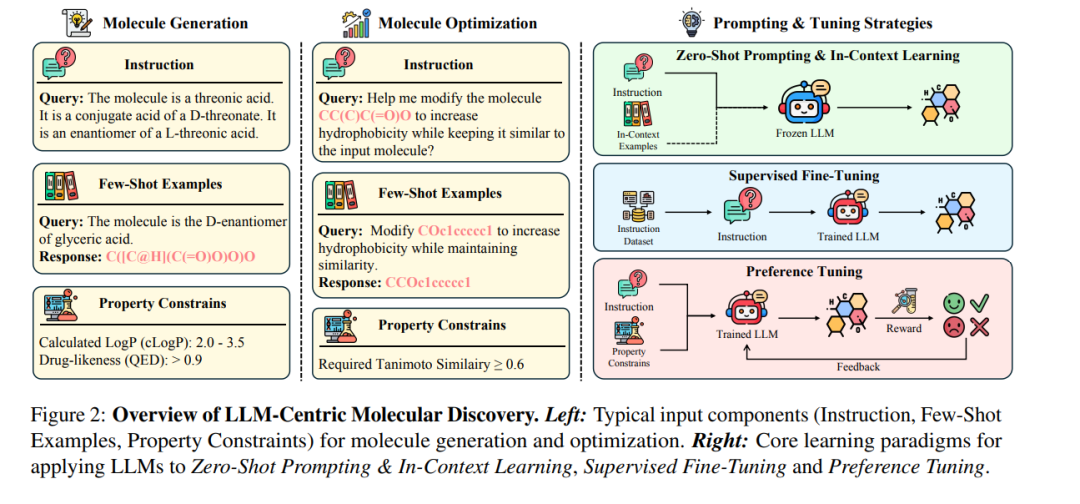
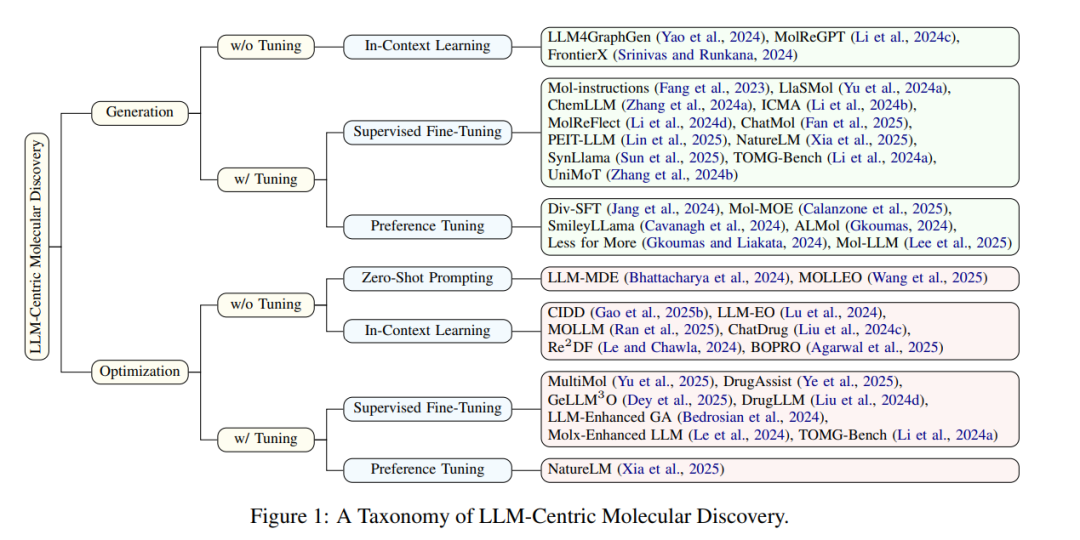
尽管LLMs在分子发现任务中的应用兴趣日益增长,但现有的综述文献尚未对该交叉方向进行系统分析。此前的大多数综述(Cheng 等,2021;Zeng 等,2022;Tang 等,2024;Yang 等,2024)主要聚焦于通用的深度生成方法,而非专门讨论LLMs的独特贡献。另一些提及LLMs的综述(Ramos 等,2025;Zhang 等,2025;Guo 等,2025;AbuNasser,2024;Janakarajan 等,2024;Liao 等,2024)则多集中于化学领域本身,或只涉及不具备LLMs涌现能力的小规模语言模型。 为填补这一关键空白,本综述首次聚焦LLMs在分子发现中的生成作用,重点探讨两个核心任务:分子生成与分子优化。我们具体分析LLMs在探索与操控复杂化学空间中的应用方式、模型适配与训练策略,并与仅作为特征提取或控制工具的辅助应用(如 Liu 等,2023;Liu 等,2024a)加以区分。 与以模型架构为分类依据的传统综述(如 AbuNasser,2024;Janakarajan 等,2024)不同,我们引入了基于学习范式的新分类体系,更好地反映LLMs在分子生成任务中的使用方式与效果。如图1所示,我们将方法划分为无需模型微调的策略(如零样本提示 Zero-Shot Prompting 和上下文学习 In-Context Learning)与需微调的策略(如有监督微调 Supervised Fine-Tuning 和偏好调优 Preference Tuning),以帮助研究者更系统地理解各类策略的优势与局限性。
总结来说,本综述在以下几个方面作出了贡献:
提出新的分类体系:我们依据学习范式而非模型结构,对现有研究进行分类,揭示LLMs能力的不同利用方式及其优劣。 * 系统梳理数据资源与评估指标:总结当前常用的数据集、基准与评估方法,便于研究者参考与比较。 * 识别关键挑战并展望未来方向:明确当前存在的研究瓶颈,并提出值得进一步探索的研究方向,助力该领域的持续发展。